

티스토리 뷰
목차
이것저것 찾아다니며 공부하는 게 지치면 정리된 글을 읽고 싶어 진다.
해서 아무런 특별한 의도도 없이 구글 스칼라에 Microservice Architecture를 검색해
가장 최근의 논문을 읽어보았다.
Revisiting the practices and pains of microservice architecture in reality: An industrial inquiry
Seeking an appropriate architecture for the design of software is always a challenge. Although microservices are claimed to be a lightweight architect…
www.sciencedirect.com
제목은 <Revisiting the practices and pains of microservice architecture in reality: An industrial inquiry>,
번역 및 요약하자면 <현실에서 MSA의 실행과 고민: 산업 조사> 정도가 될 수 있겠다.
대충 초록을 훑으면 20개의 소프트웨어 회사를 대상으로 아래와 같은 질문을 활용해 데이터를 모은 뒤

제목에 걸맞은 데이터를 뽑아 정리했다고 한다. 목적은 MSA의 이상과 현실에 대한 갭을 조사하기 위해.
논문에서는 대략 8가지로 나누어서 실제 실행과 거기서 발생하는 고민에 대해 정리하고 있는데,
가능할지 모르겠지만 하나씩 정리해 보자.
Componentization via services - 서비스를 통한 컴포넌트화
Practice 1: Independence by seperation - 분리를 통한 독립성
마이크로서비스는 특정한 방식으로 소통하는, 프로세스 밖의 컴포넌트로 정의된다.
또한 컴포넌트화의 이점은 마이크로서비스의 독립성 혹은 자율성이라고 할 수 있다.
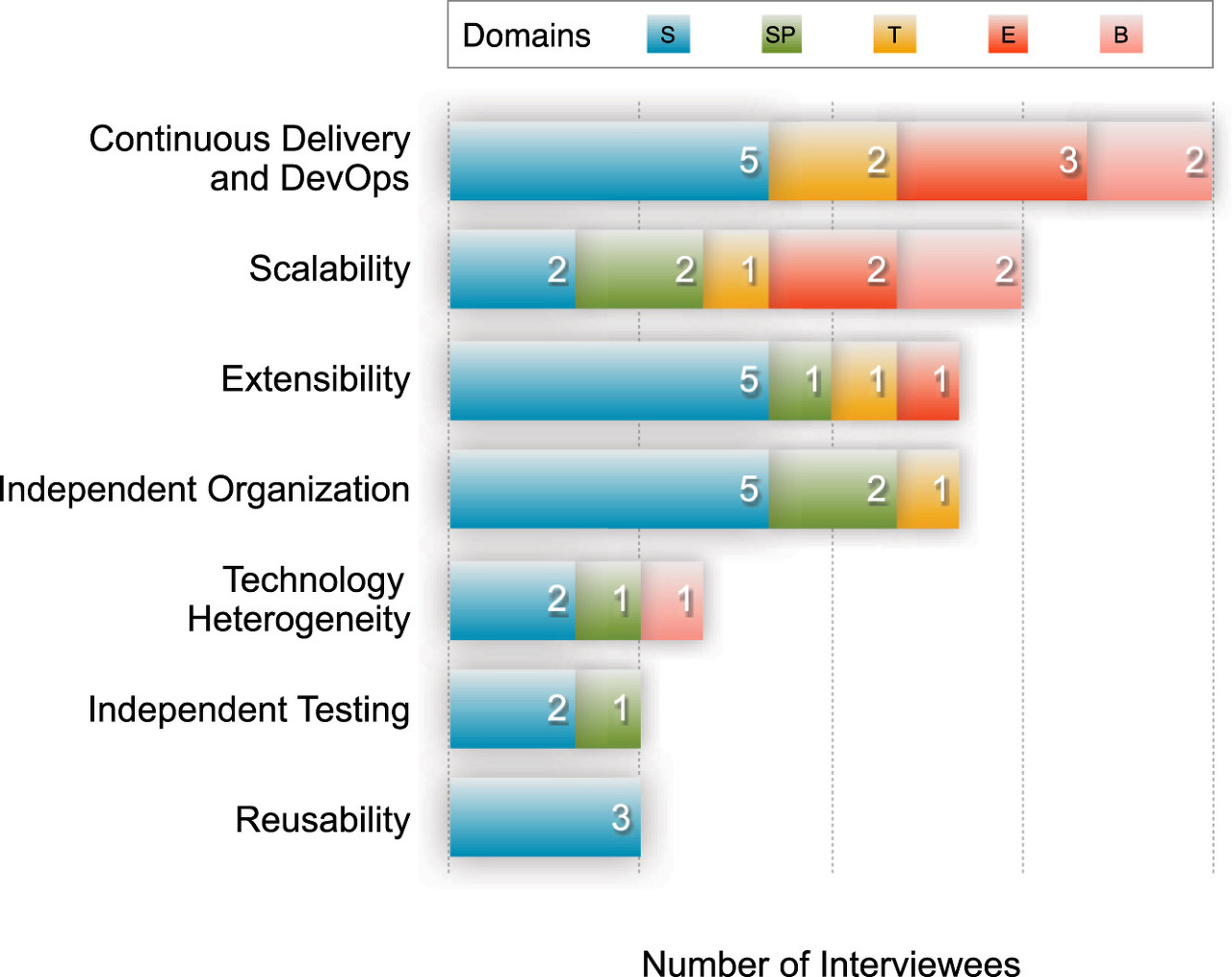
이는 위 표에서 확인할 수 있듯이 CD와 DevOps측면에서 MSA에 대한 동기부여가 이루어지는 것과 관련 있으며,
실무자들은 다른 것보다 배포와 운영 관점에서 MSA를 도입하는 것으로 보인다.
Pain 1: Chaotic independence
논문의 노트에는 Chaotic을 아래와 같이 표현하고 있다.
“Chaotic” represents that it is difficult to understand the internal behavior of the system, and it is difficult to improve the performance of service nodes in the call chain, thus affecting the overall situation.
짧게 요약하면 'Chaotic'이란 내부 동작의 파악이나 퍼포먼스 개선이 어려워 전체적인 영향을 끼친다는 뜻이다.
쉽게 말해 MSA의 독립성이 적절하게 구성되지 않으면 해당 독립성이 이득이 아닌 비용으로 전환된다는 뜻이다.
여기에 몇 가지 예를 드는데, 요약하면 아래와 같다.
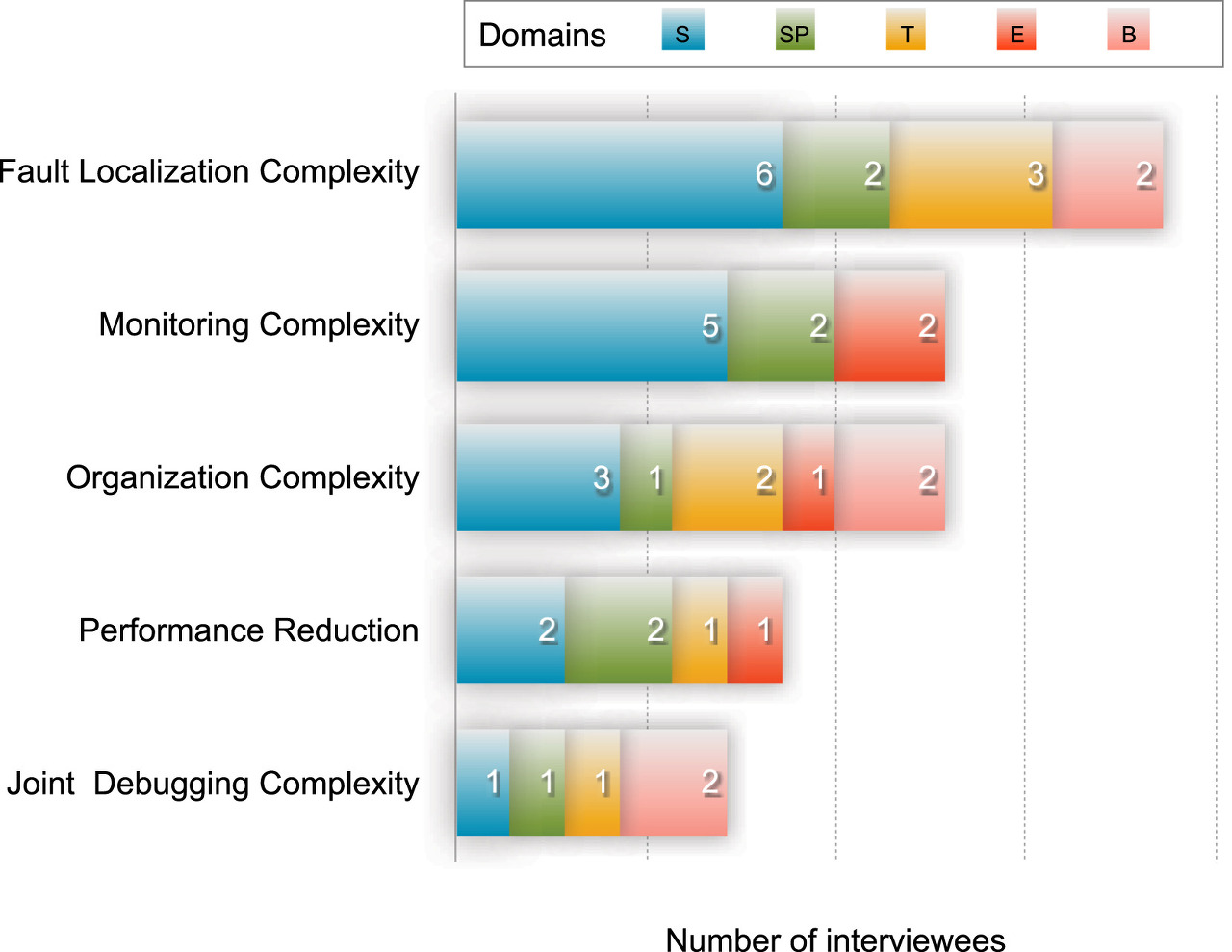
- 부적절한 경계선 설정
- 길게 늘어지는 콜 체인과 그 안의 여러 서비스에서 동시에 발생하는 에러
- 모니터링과 구조화 문제
- 콜 체인 간의 상호작용에 드는 비용
- 하나의 기능 개발 혹은 변경이 여러 개의 마이크로서비스에 영향
- 버전관리와 디버깅의 어려움 - 여러 서비스에서 동시다발적인 디버깅 요구 발생
- IT 업체 - 모니터링 및 성능 저하
- 이커머스 업체 - 모니터링의 복잡성
- 금융 업체 - 나머지 모든 문제
Organized around business capabilities - 비즈니스 능력 중심의 조직화
Practice 2: Organizational transformation - 조직 개편
콘웨이의 법칙에 따르면 기술 구조는 조직구조와 상호 연관성이 존재한다.
또한 Fowler와 Lewis의 제안에 따르면 조직 내에서 팀은 마이크로서비스의 비즈니스 능력에 따라 분할되어야 하며
하나의 상품 혹은 컴포넌트는 그것을 위한 전용 팀이 개발하고 운영해야 한다.
아래는 인터뷰 응답자들의 답변 목록이다.
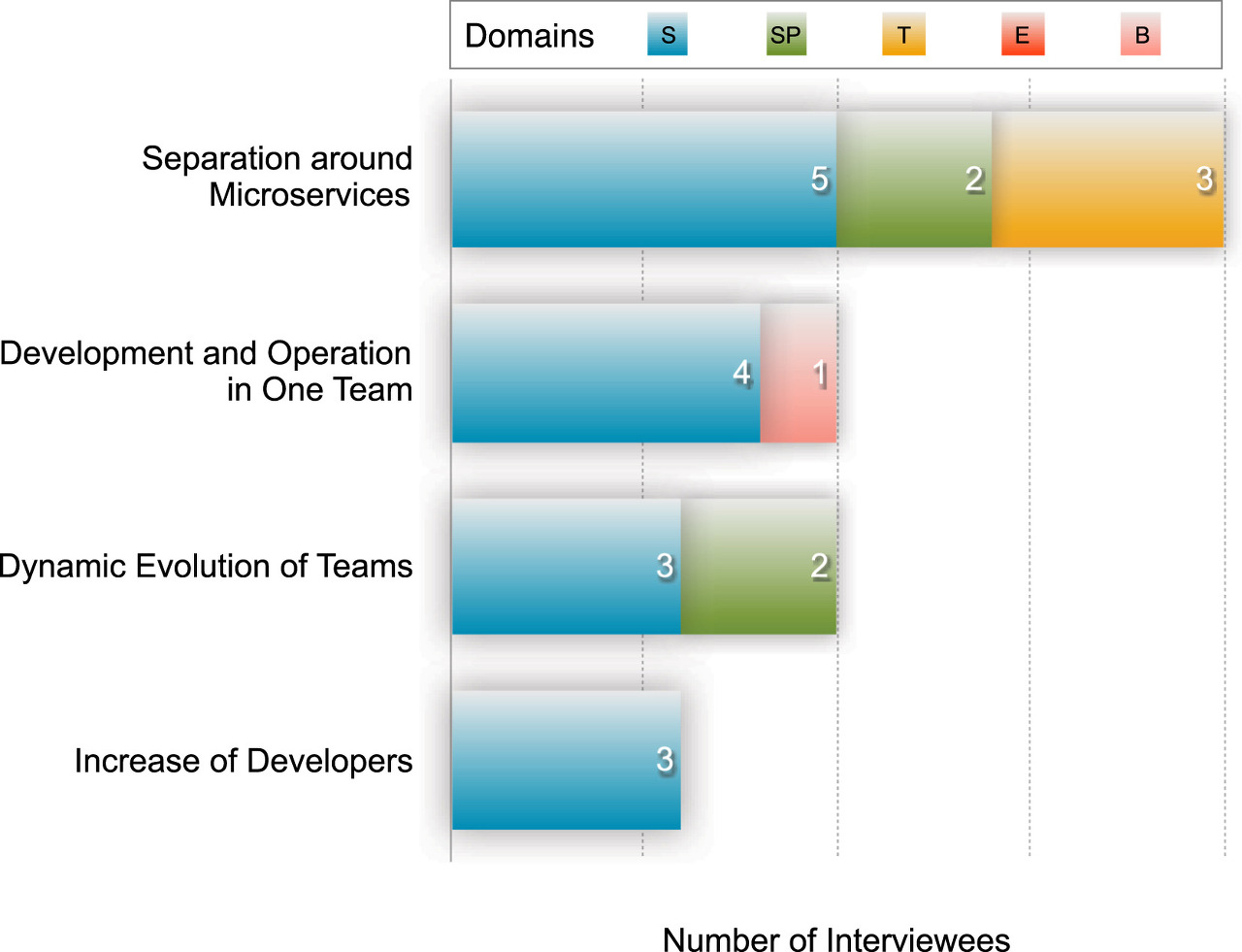
거의 50%에 해당하는 사람들이 위와 같은 생각에 동의하는 것을 확인할 수 있다.
그들은 또한 마이크로서비스가 팀 분할을 유도하고, 그에 따라 팀 사이의 의존도와 상호작용이 줄어들어
결과적으로 관리 비용이 줄어들 것이라고 언급하기도 했다.
이와 반대로 팀 구조 역시 마이크로서비스의 분해와 기술 구조에 영향을 끼칠 수 있다.
응답자들은 레거시 시스템의 분할이나 새로운 마이크로서비스의 디자인에도 팀 구조를 고려한다.
“The ideal is that the development of one microservice could be assigned to 1 to 2 developers.
Having 3 to 5 developers to some extent indicates that the microservice can be further partitioned...”
마이크로 서비스 개발에는 최대 2명의 개발자가 적절하며 그 이상은 팀을 분할할 여지가 남아있다는 언급이다.
하지만 대부분의 업체에선 인력부족으로 정확하게 이처럼 팀이 구성되지 않고,
마이크로서비스의 성장과 개발 작업 부하의 감소에 따라 동적으로 팀이 구성되며
하나의 팀에서 여러 마이크로서비스를 개발하는 경우도 있다.
Pain 2: Ad-hoc organizational transformation
번역해 보자면 즉흥적이고 임시적인 조직 개편이라고 할 수 있을 것이다.
이 단락의 맥락에서는 정확한 전략이 아닌, 경험에 의존한 임시적인 방식을 가리킨다.
이와 같이 즉흥적이고 임시적으로 개편한 조직은 독립적이니 분해를 보장하기 어려우며
이는 마이크로 서비스 간의 결합도를 들쭉날쭉하게 만들며 디버깅 시 개발 효율을 오히려 떨어뜨릴 가능성이 있다.
“We are aware that the organization should catch up with the change of architecture accordingly, but we lack the guide on how to do it. Most importantly, we need the approval of the decision makers...”
실무자도 조직 개편에 대한 필요성은 인식하고 있으나,
그에 맞는 명확한 가이드가 없기 때문에 의사결정자의 올바른 승인이 필요하다는 뜻이다.
Smart endpoints and dumb pipes
주석
Smart endpoints and dumb pipes는 MSA의 설계원칙 중 하나로, 엔드포인트가 비즈니스 로직을 모두 처리하며(똑똑한 엔드포인트) 데이터 전송과 같은 네트워크는 말 그대로 파이프의 역할만 해야 한다(멍청한 파이프)는 뜻이다. 그 목표는 각 마이크로서비스가 독립적으로 개발 및 배포되는 것이며, 올바른 통신환경을 제공하는 것이다.
Practice 3: Choosing communication protocol
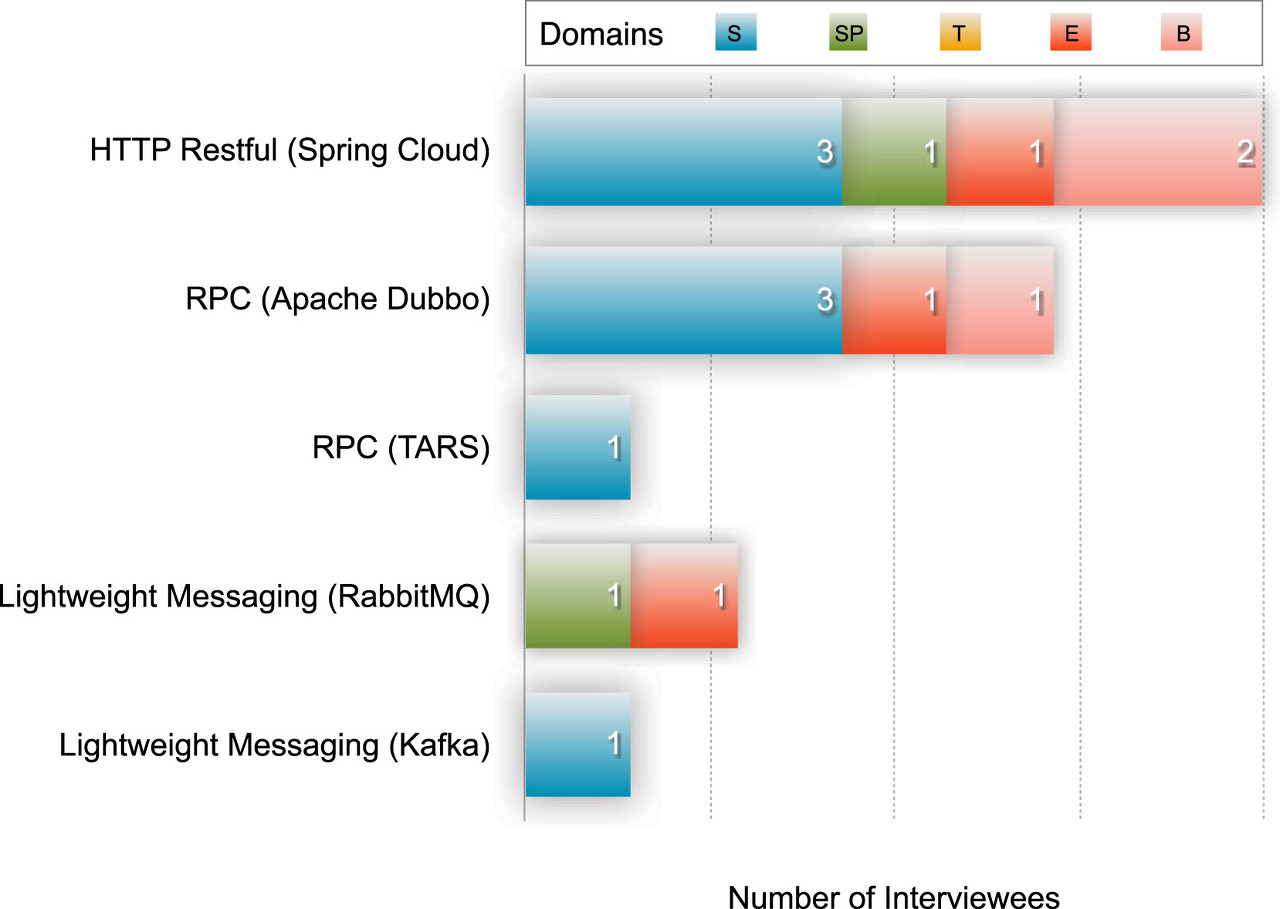
이 섹션에서는 실제로 서비스 간 통신에 실무자들이 어떤 프로토콜을 사용하는지 정리한다.
지금 정리하기엔 과한 여러 가지 프로토콜이 나열되며, 방화벽을 통과하지 못하는 RPC를 사용하는 것과
성능이 낮고 복잡성이 높은 Restful 방식을 가장 많이 사용하고 있다고 한다.
Rabbit MQ나 Kafka와 같은 경량 메시징 프레임워크도 도합 15%나 사용되지만,
소프트웨어/IT 업체와 금융권은 모두 Http Restful API 혹은 RPC를 사용한다고 한다.
Pain 3: Complexity of API management
위 섹션에도 나왔지만 MSA 통신에서 마주치는 가장 큰 문제는 구현과 관리의 복잡성이다.
또한 팀별로 API에 대한 이해가 다를 수 있으며 이는 독립적인 서비스 배포와 합쳐져 문제를 제때 발견하기 어렵게 만든다.
이와 같은 이해를 모든 팀에게 일관되게 유지시키는 것은 매우 어렵기 때문에,
네이밍 규칙 같은 것을 포함한 내부규정을 정해 API 개발을 표준화하기도 한다.
Decentralized governance
주석
Decentralized governance는 번역하면 '분산형 지배'정도가 된다. 중앙 집권식 의사결정이 아닌 분산된 시스템에 소속된 사람들이 공동으로 의사 결정을 내리고 상호작용 함으로써 시스템의 안정성과 효율성을 유지하는 것이 목적이다. 또한 제대로 작동하는 경우 불필요한 중앙의 개입을 최소화하며, 의사 결정의 투명성과 공정성을 확보할 수 있다.
Practice 4: Support of technology diversity
말 그대로 다양한 언어, 프레임워크, 디비의 다양함을 보장한다는 의미다.
분산된 시스템은 독립성을 보장받기 때문에 한 시스템 안에서도 여러 가지 언어와 프레임워크가 사용될 수 있다.

여러 가지 분야에서 기술자를 구하기 쉬운 자바가 주로 사용되지만,
다양한 유형의 문제에 맞춰 여러가지 언어를 사용하는 것이 가능하며 또 실제로 이루어지고 있다.
하지만 너무 다양한 기술 스택은 버전관리를 힘들게 하기 때문에 제어가 필요하다는 의견 역시 있다.
추가로 통신 도메인의 실무자들은 성능상의 이유로 자바보다 C, C+, Go를 사용한다고 한다.
Pain 4: Excessive technology diversity
번역하면 과도한 기술 다양성이 될 것이다. 위에서 언급한 대로, MSA는 다양한 기술 스택을 섞어서 사용할 수 있다.
이는 개발자의 성장을 요구하며 구현과 학습의 복잡도를 증가시킨다.
응답자 중 20%의 인원이 기술 아키텍처의 결정이 높은 우선순위를 가져야 한다고 제안했는데,
이는 새로운 기술과 프레임워크에 대한 학습과 설정 과정에 예상보다 많은 시간이 소요될 수 있기 때문이다.
즉, 기술 스택을 느긋하게 선택하고 구현을 시작했다간 예상치도 못한 지연이 생길 가능성이 있다.
Decentralized data management - 데이터 분산 관리
Practice 5: Compromise with database decomposition
데이터 분산 관리는 데이터를 중앙이 아닌 분산된 시스템이 관리하는 것을 가리킨다.
이때 사용되는 것이 분산된 디비 혹은 블록체인과 같은 기술이며, 이를 통해 데이터 관리의 보안성과 신뢰성을
높이고 데이터에 대한 접근과 그 처리의 성능을 향상하는 것이 목적이다.
하지만 인터뷰에서 실제로 디비를 분할한 경우는 3명에 불과했는데, 응답자의 60%는 아래와 같은 이유로
디비 분할을 고려하지 않았다고 한다.
- 인메모리 데이터베이스 사용
통신 분야의 세 응답자는 전통적인 시스템 대신 인메모리 디비를 사용한다고 답했다.
이때 데이터는 본질적으로 마이크로서비스에 묶여있기 때문에 디비를 분해할 필요를 느끼지 못했다. - 레거시 시스템에서 디비 분할
기존 시스템에서 이미 스냅샷과 Binlog 같은 기술을 이용해 테이블을 분리.
해당 설계가 MSA의 요구조건을 충족한다고 생각해 더 이상의 분할은 고려하지 않음. - 분할에서 얻는 이득 분석
디비 분할이 물론 마이크로서비스 결합도 감소에 도움이 되지만, 분할 이후 겪어야 할 문제가 막대하다고 판단.
따라서 실무자들은 문제를 피하기 위해 공유 디비를 계속 사용하는 것을 선호한다.
“We thought it was easy, so we unhurriedly selected and constructed the technology stacks only after the microservices having been decomposed from the legacy system. As a result, no product was delivered in the following two months, because all people were busy coping with the problems of excessive technology stacks...”
대충 관리와 데이터 정합성을 지키기 어렵고 데이터의 양에 따라 오히려 성능 문제가 발생해서
백엔드의 디비 분할은 잘 고려되지 않는다는 발언이다.
Pain 5: Data inconsistence
위에서 언급된, 그리고 당연히 발생할 수 있는 데이터 불일치 문제이다.
MSA로의 마이그레이션 이후 데이터 정합성을 보장하면서 분산 트랜잭션을 다루는 일은 굉장히 복잡하기 때문이다.
물론 데이터의 일관성 문제는 모놀리식 아키텍처에서도 발생하지만 이 경우는 작업을 하나의 트랜잭션으로
묶어 처리함으로써 해결할 수 있다.
응답자 중 한 명은 기업들이 CAP가 아닌 결과적 정합성(Eventual Consistency)을 선호한다고 언급했는데,
이 결과적 정합성이란 설계와 구현이 복잡하며, 정합성 확보를 위해 수동적인 개입이 필요해지는 등
굉장히 복잡한 과정을 거쳐야 하기 때문에 마이그레이션 후 개발자들에게 고통을 주고 있다.
Infrastructure automation
주석
인프라 자동화는 말 그대로 서버, 네트워크, 보안 설정등 인프라를 코드 수준에서 자동화하며 클라우드 인프라를 이용해 리소스를 관리하는 것을 가리킨다. 이를 통해 사람의 개입을 최소화함으로써 오류를 방지하고, 정합성을 유지하는 것이 목표이다.
Practice 6: CI & CD
마이크로서비스 팀은 지속적 통합과 지속적 배포에 풍부한 경험을 갖고 있다.
여기에 적절한 인프라 자동화가 적용되면, 마이크로서비스의 배포는 모놀리식 시스템만큼 간단해진다.
이어서 이 섹션에서는 응답자들이 사용하는 자동화 도구에 대해 수집한 결과를 보여준다.
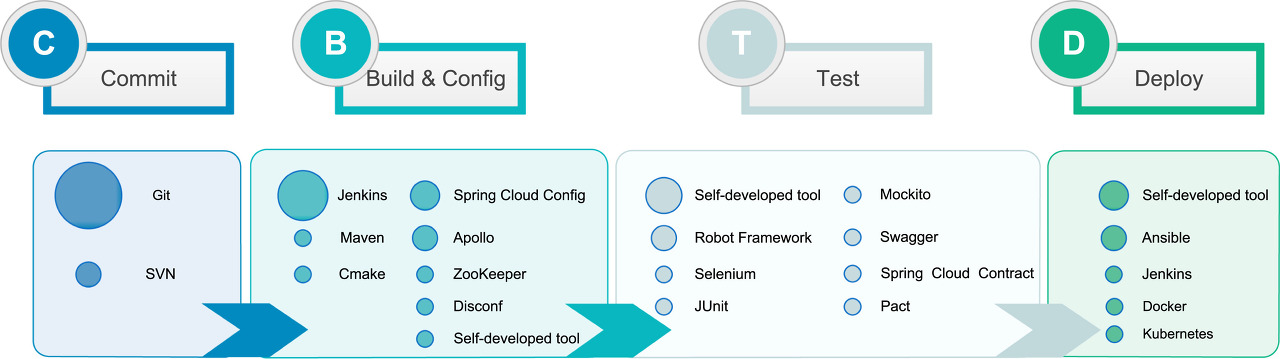
흥미로운 부분은 개발자들이 테스트와 배포에 있어 자체 개발한 도구를 선호한다는 것이며,
젠킨스의 경우 빌드부터 배포까지 커버할 수 있어 인기가 많다.
이어서 아래의 그림은 응답자가 실제로 채택한 테스트 전략이며, 상세한 도구는 그 아래에 이어진다.
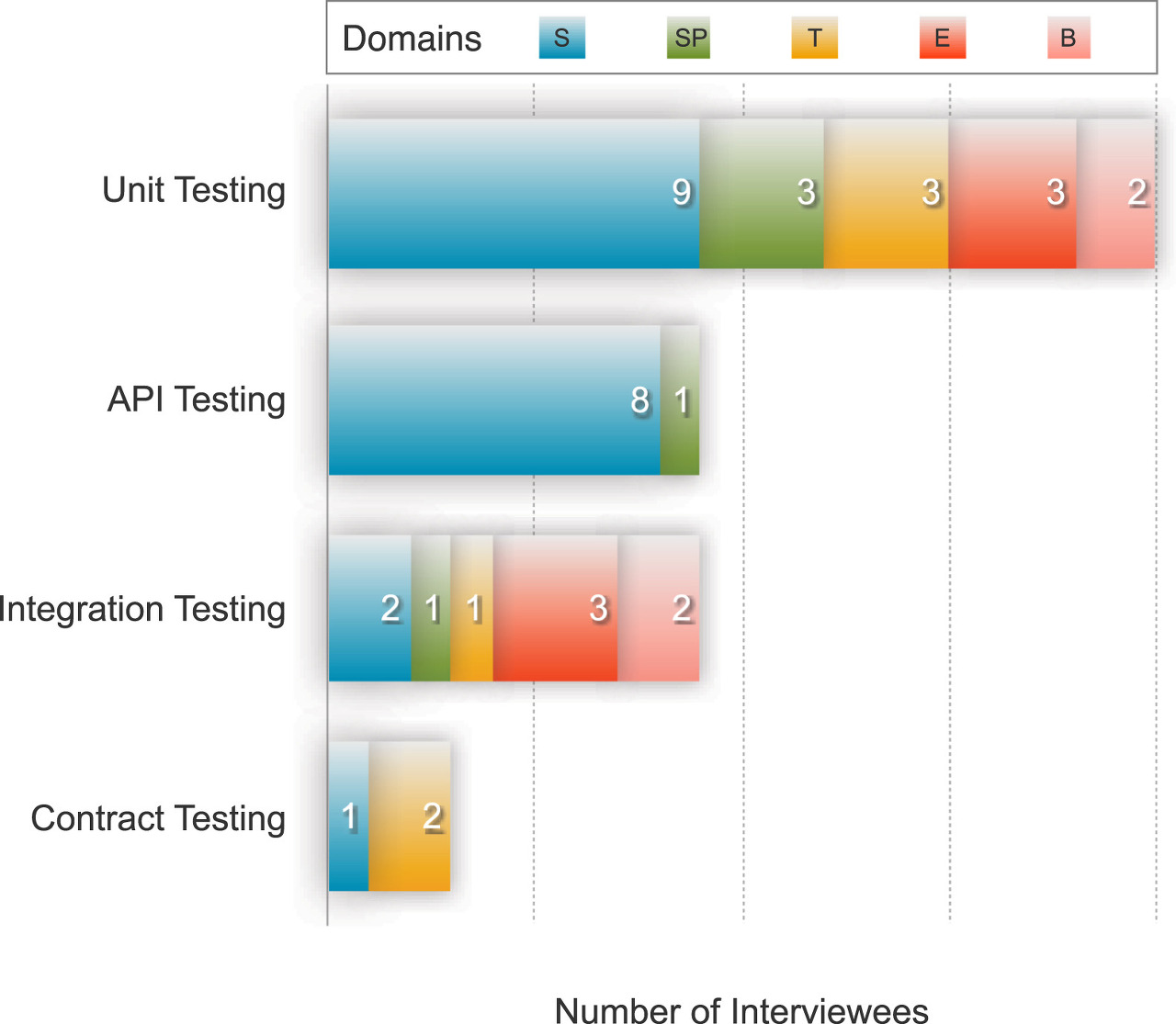
- Unit Testing - JUnit, Mockito
- API Testing - Swagger
- Integration Testing - Unit 테스트와 API 테스트로 분할하여 문제를 빠르게 찾을 가능성을 높임
- Contract Testing - Spring Cloud Contract, Pact
Pain 6: Inadequate automation
섹션의 맥락에서 봤을 땐 불충분한 자동화로 번역하는 것이 타당해 보인다.
응답자의 30%가 높은 수준의 인프라 구축에 있어서 기존 프레임워크에 부족한 점이 있다고 생각한다.
또한 인프라 자동화의 중요한 부분인 마이크로 서비스 거버넌스(Practice 7 참조)에서도 어려움을 겪고 있으며,
그 예로는 자동 스케일링과 경험에 의존하지 않는 자동 임계값 설정 등이 포함된다.
아래의 목록은 응답자가 답변한, MSA가 가져오는 테스팅 자동화에 대한 도전과제이다.
- 통신 비용이 높다
서로 다른 팀에 의해 개발되어 통신을 통해 데이터를 주고받는 MSA의 특성상 유지보수 역시 독립적이다.
서비스가 변경되거나 업그레이드되면 호환성에 문제가 생길 수 있으며, 팀 간 통신 비용은 증가하고
테스트 자동화는 복잡해질 가능성이 있다. - 검증 비용이 높다
마이크로서비스의 검증을 위해선 각 서비스를 위한 인프라(디비 등)가 구축되어야 하며, 이는 비용으로 이어진다.
추가로, 서비스의 작동 확인을 위한 배포 및 구성과 같은 프로세스에 시간이 많이 소요된다. - 불안정한 결과를 처리하는데 드는 비용이 높다
네트워크 지연, 타임아웃, 대역폭 등은 제어를 벗어난 테스트 결과를 초래할 수 있다. - 통합 테스트(Integration Testing) 비용이 높다
모놀리식 프로그램보다 많은 단위가 독립적으로 배포되어 통합 테스트가 어렵다.
서비스에 따라 팀 역시 분할되어 있기 때문에 소비자가 테스트를 수행할 때 각 서비스 팀과 속도가 맞지 않을 수 있다.
이로 인해 불필요한 대기시간이 발생하며, 통합 테스트의 피드백 주기가 기존에 비해 길어질 수 있다.
Design for failure - 오류를 상정한 설계
Practice 7: Microservices governance
"Design for failure"는 마이크로서비스를 위한 섬세한 거버넌스 설정에 의존하며 다음과 같은 특성을 강조한다.
- 장애를 막거나 특정하기 위한 모니터링과 로깅
- 마이크로서비스를 장애에서 회복시키는 장애 허용 메커니즘
계속해서 아래는 응답자들이 축적된 실무 경험을 바탕으로 대답한 실천 방법들이다.
- 모니터링과 로깅
마이크로서비스의 장애를 지역화하기 위해 응답자들은 로그 분석, 자동 경고, 콜 체인 추적과 대시보드를 사용했다.
30%의 응답자는 로그의 모니터링과 검색 및 시각화를 위해 ELK 스택을 사용했으며
45%는 모니터링에 자동 경고를,
35%는 분산 추적 시스템이니 Zipkin 및 Pinpoint를 이용해 콜 체인에 관한 문제 해결을
35%는 Zabbix, Grafana, Kibana 및 자체 개발 도구를 이용해 모니터링을 하고 있다.
실시간 모니터링을 통해 다양한 메트릭을 확인할 수 있으며, 20명 중 10명, 혹은 11명이
CPU, 메모리, 콜 체인 그래프와 트랜잭션 건수, 성공률과 관련된 메트릭을 모니터링하는 것에 대해 언급했으며
30%가 Prometheus를 가장 뛰어난 모니터링 툴로 뽑았는데, 이는 인프라, 서비스, 애플리케이션과 미들웨어에 대한
통합된 솔루션을 제공하기 때문이다.
또한 MSA 기반 시스템의 고가용성을 구현하기 위해선 장애에 대한 예방과 특정만큼 장애 내성이나 복구 역시 중요하다.
- 응답자 중
30%는 Circuit Breaker 패턴 - Hystrix를 사용하여 구현
35%는 Rate Limiting 패턴 - 각 유형의 요청에 대한 최대 QPS(Query Per Second) 임계값 설정
30%는 Degradation 패턴 - 전체 시스템의 부하에 대한 임계값 설정
을 사용하는 것으로 나타났다.
Pain 7: Unsatisfying monitoring and logging
Pain 6과 비슷하게, 실무자들은 MSA에 대한 모니터링에 대해 만족하지 못하는 것으로 나타났다.
그 원인은 크게 네 가지 측면으로 기술되며, 요약하면 아래와 같다.
- 자동화된 운영의 부족
30%의 응답자가 현재의 자동화가 만족스럽지 않다고 답변했다.
여전히 일부 운영은 수동 로깅에 의존하며, 이는 시간이 들고 효율적이지도 않다. - 트러블슈팅의 어려움
마이크로서비스 기반 시스템은 수백 개의 마이크로서비스 인스턴스를 포함할 수 있기 때문에
그 가운데에서 문제를 찾는 것은 실무자에게 어려운 일이다.
25%의 응답자가 여전히 로깅과 분산 추적 같은 오래된 방법을 사용한다고 응답했다. - 임계값 설정의 어려움
MSA 기반 시스템에서 적절한 경고 임계값을 설정하는 것은 실무자에게 고통스러운 일이며,
이는 여전히 과거의 경험에 의존하고 방법론적인 가이드가 부족하기 때문이다.
부적절한 임계값은 이어지는 오판이나 누락, 비정상적인 상황과 장애를 동반한다.
게다가 임계값은 끊임없이 지능적인 조정을 요구하며, 이는 인공지능을 이용한 AIOps가 주목하는 분야이다. - 종합 모니터링 시스템의 부재
응답자의 30%는 인프라, 애플리케이션, 마이크로서비스 및 미들웨어를 포함한 다양한 차원에서
모니터링 및 시각화를 제공할 수 있는 플랫폼을 원한다고 밝혔다.
이는 단일 지표만을 모니터링하는 일부 플랫폼으로의 전환이 어렵기 때문이며,
Prometheus는 여러 지표를 모니터링하는 강력한 툴이지만 시각화에 필수적인 로깅 기능을 지원하지 않고
엔터프라이즈 환경에 필요한 장기 저장 기능이나 이상행동 감지, 자동 스케일링 및 사용자 관리나
대시보드 솔루션이 없고 PromQL을 위한 단순한 UI만을 제공한다.
Evolutionary design - 단계적인 진화를 위한 설계
Practice 8: Stepwise evolution
마이크로서비스의 진화라는 관점에서, 응답자들의 경험과 실천으로부터 두 가지 패턴이 추출되었다.
- Demolition Pattern
레거시 시스템에서 MSA로의 전환을 한 번에 실행하거나 아예 새로운 마이크로서비스 시스템을 개발하는 패턴이다.
이는 25%의 응답자가 사용한다고 답했으며, 일반적으로는 Strangler Pattern을 선호한다. - Strangler Pattern
레거시 시스템을 급격하게 이전하는 것이 아닌 특정 기능부터 단계적으로 분리해 전환하는 패턴이다.
이 방식은 주로 통신 업체, 이커머스, 그리고 금융 업체가 사용한다.
레거시 시스템에서 MSA로의 Strangler Pattern의 적용은 실무자에게 크게 아래와 같은 두 가지 고민을 던져준다.
- 레거시 시스템에 대한 이해
마이크로서비스에 대한 지식을 얻으려면 레거시 시스템의 비즈니스 로직과 구조에 대해 이해하는 것이 필요하다.
응답자들은 이를 위해 시니어 개발자, 아키텍트, 설계 문서가 중요한 역할을 한다고 밝혔다.
하지만 다섯 명의 응답자는 레거시 시스템이 오래되고 필요한 설계 문서가 없어 어려움을 겪었다고 밝히기도 했다.
이런 상황에서 실무자들은 코드를 읽고 분석해 컴포넌트 사이의 의존성을 밝히는데 비용을 사용하는 것 외에는 방법이 없다.
게다가 이런 시스템의 기술 스택은 시대에 뒤떨어져 있어서 제대로 된 리버스 엔지니어링 도구를 선택하는 것도 어렵다. - 마이크로시스템을 기반으로 한 분할
75%의 응답자는 마이크로서비스의 경계를 확인하고 적절한 마이크로서비스 후보자를 고르는 것이 중요하다고 생각한다.
MSA 기반 분할의 일반적인 원칙은 확장성과 같은 다양한 요소를 고려하는 것이다.
어떤 마이크로서비스가 분할될지는 경험 많은 아키텍트에 의해 결정된다.
일반적으로는 아래 그림과 같은 분야에서 하나 이상의 요소를 골라 순서대로 분할하는 것이다.

비즈니스 도메인은 산업에서 공통적으로 고려되는 요소이다(55%).
또한 DDD 방식은 비즈니스 도메인을 기반으로 마이크로서비스의 경계를 결정하는 데 사용되는 인기 있는 방법이다.
이어서 50%의 응답자는 MSA 기반 분할 과정에서 기존의 팀이 유지되도록 노력했다고 밝혔는데,
이는 기존의 조직이 다른 비즈니스 모듈을 기반으로 세팅되었기 때문이다.
계속해서
- 40%의 응답자는 재사용성을
- 30%가 각각 확장 가능성 있는 요구사항(extensibility requirement)과 수정 빈도를
- 20%가 각각 확장 가능한 요구사항(scalability requirement)과 기존 디비 구조를
MSA 기반 분해에 사용한다고 밝혔다.
Pain 8: Subjective microservices-oriented decomposition without an effective guide
한 마디로 요약하면, 반복해서 등장한 가이드의 부족을 가리킨다.
현실적으로 MSA 기반 분해에선 아키텍트의 경험이 중요한 역할을 하고 있으며,
응답자 중 60% 역시 체계적인 가이드가 없이 경험에 의해 이루어졌다고 언급했다.
“Experience can tell us how to do it, but it can not tell us why we should do it...”
직역하면 "경험은 우리가 어떻게 해야 하는지 알려줄 수 있지만 왜 해야 하는지는 알려주지 못합니다..."가 되겠다.
수직 분할 패턴과 DDD와 같은 이론적인 전략들이 산업에서 시도되고 있기는 하지만,
실제로는 효율적이지도 않으며 실무자들의 요구를 만족시키지도 못하고 있다.
실제로 한 응답자는 DDD를 분할에 적용하는 문제점에 대해, DDD는 추상적인 개념일 뿐이며 구체적인 프로세스 가이드가 없다고
대답하기도 했다.
더 짧게 정리할 수 있을 줄 알았는데 적다보니 중요해 보이는 부분이 많아서 분량이 뻥튀기 되었다.
처음 보는, 모르는 단어는 메모장에 한가득 쌓였고.
그래도 재미있었다. 끝!
'Development > Paper Review' 카테고리의 다른 글
- Total
- Today
- Yesterday
- 파이썬
- RX100M5
- 자바
- 알고리즘
- 유럽여행
- 칼이사
- 야경
- 세모
- 중남미
- 기술면접
- 여행
- 백준
- 스트림
- Backjoon
- Algorithm
- BOJ
- 리스트
- 유럽
- 스프링
- 면접 준비
- a6000
- spring
- Python
- 맛집
- 동적계획법
- java
- 세계여행
- 세계일주
- 지지
- 남미
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |