

티스토리 뷰
[FastAPI]SQLAlchemy + Pydantic을 이용한 게시판 만들기-(3)S3 버킷을 이용한 사진 업로드
Vagabund.Gni 2023. 10. 12. 11:16목차
FastAPI + SQLAlchemy + Pydantic을 이용한 게시판 만들기
[FastAPI]SQLAlchemy + Pydantic를 이용한 게시판 만들기-(1) 회원가입 및 로그인 구현(JWT)
[FastAPI]SQLAlchemy + Pydantic를 이용한 게시판 만들기-(1.5) 디테일 수정
[FastAPI]SQLAlchemy + Pydantic를 이용한 게시판 만들기-(2-1)Feed CRUD - Model, Service
[FastAPI]SQLAlchemy + Pydantic을 이용한 게시판 만들기-(2-2)Feed CRUD - Routes, main.py
[FastAPI]SQLAlchemy + Pydantic을 이용한 게시판 만들기-(3)S3 버킷을 이용한 사진 업로드
[FastAPI]SQLAlchemy + Pydantic를 이용한 게시판 만들기-(4-1)Comment CRUD - Models, Services
[FastAPI]SQLAlchemy + Pydantic를 이용한 게시판 만들기-(4-2)Comment CRUD - Routes, main.py
지난 글까지 해서 회원 가입 및 로그인, 그리고 JWT 검증을 사용한 게시글 CRUD를 구현해 보았다.
이번 글에서는 그 후속 작업으로, 게시글 업로드 시 사진도 함께 올릴 수 있게 할 예정이며,
당연히 S3 버켓을 만들어서 진행할 예정이다.
먼저 설치해야 할 라이브러리는 다음과 같다.
pip install boto3AWS S3 버켓은 이미 만들어둔 상태라고 가정하겠다.
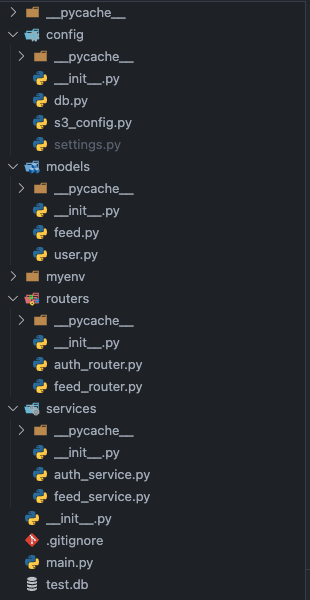
추가로 이 글이 끝나고 난 뒤의 프로젝트 아키텍처는 다음과 같다.
settings.py
먼저 S3버킷에 접근하기 위한 설정을 하고 들어가자.
환경변수를 관리하기 위해 settings.py에 다음과 같은 내용을 넣어준다.
S3_ACCESS_KEY = IAM 사용자 액세스 키
S3_SECRET_KEY = IAM 사용자 시크릿 키
S3_BUCKET = 사용할 버킷 이름이어서 해당 파일을 .gitignore에 등록해 공개 레포지토리에 올라가지 않도록 한다.
#.gitignore
settings.py
s3_config.py
다음으로는 S3 클라이언트 초기화이다.
사용할 때마다 초기화해서 사용하는 것도 가능하지만 여기서는 한 곳에 초기화를 해두고 임포트 해서 쓰기로 한다.
import boto3
from config import settings
s3_client = boto3.client(
"s3",
aws_access_key_id=settings.S3_ACCESS_KEY,
aws_secret_access_key=settings.S3_SECRET_KEY,
region_name="ap-northeast-2",
)가장 먼저 위에서 설치한 boto3을 임포트 하고, 그다음으로 설정한 settings를 가져온다.
이어서 boto3.client()를 호출해 S3 클라이언트 객체를 생성하고 s3_client에 저장한다.
feed.py
계속해서 모델 파일을 수정하자. 복수의 이미지 URL을 저장할 수 있도록 다음과 같이 구성한다.
from sqlalchemy import Column, String, Integer, ForeignKey, JSON
from sqlalchemy.orm import relationship
from config.db import Base
from pydantic import BaseModel
from typing import List, Optional
class Feed(Base):
__tablename__ = "feeds"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
content = Column(String)
author_email = Column(String, ForeignKey("users.email"))
image_urls = Column(JSON, nullable=True)
author = relationship("User", back_populates="feeds")
class FeedCreate(BaseModel):
title: str
content: str
image_urls: Optional[List[str]] = []
class FeedUpdate(BaseModel):
title: str
content: str
image_urls: Optional[List[str]] = []
class FeedInDB(FeedCreate):
pass
class FeedResponse(FeedCreate):
id: int
author_email: str
author_nickname: str
image_urls: Optional[List[str]]달라진 부분만 짚고 넘어가자.
class Feed(Base):
__tablename__ = "feeds"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
content = Column(String)
author_email = Column(String, ForeignKey("users.email"))
image_urls = Column(JSON, nullable=True)
author = relationship("User", back_populates="feeds") image_urls = Column(JSON, nullable=True)먼저 SQLAlchemy 모델에 image_urls를 정의한다.
형식은 JSON이며, nullable이고, 0개에서 N개까지의 이미지 주소를 저장할 수 있다.
class FeedCreate(BaseModel):
title: str
content: str
image_urls: Optional[List[str]] = []
class FeedUpdate(BaseModel):
title: str
content: str
image_urls: Optional[List[str]] = [] image_urls: Optional[List[str]] = []피드 생성과 수정에서는 이미지 URL 목록을 Optional로 받는다. 기본 값은 빈 리스트이다.
class FeedResponse(FeedCreate):
id: int
author_email: str
author_nickname: str
image_urls: Optional[List[str]]응답으로 반환할 스키마에도 이미지 URL 목록을 위한 Optional 필드를 추가해 준다.
여기서 기본 값을 설정하지 않은 이유는 여러 가지가 있지만, 기본적으로는 DB와의 일관성을 위한 것이다.
정보가 없는('None')것과 빈 리스트와는 차이가 있기 때문이다.
feed_service.py
계속해서 서비스 로직을 작성해 보자. 변경사항이 제법 많다.
from fastapi import HTTPException, UploadFile
from sqlalchemy.orm import Session
from sqlalchemy import join
from models.feed import Feed, FeedCreate, FeedUpdate
from models.user import User
from config import settings
from typing import List, Optional
import uuid
from config.s3_config import s3_client
import logging
logging.basicConfig(level=logging.NOTSET)
def create_feed(db: Session, feed: FeedCreate, author_email: str, images: List[UploadFile] = None):
feed_dict = feed.model_dump()
feed_dict["author_email"] = author_email
if images:
image_urls = upload_image_to_s3(images)
feed_dict["image_urls"] = image_urls
author = db.query(User).filter(User.email == author_email).first()
if author is None:
raise HTTPException(status_code=404, detail="Author Not Found")
author_nickname = author.nickname
db_feed = Feed(**feed_dict)
db.add(db_feed)
db.commit()
db.refresh(db_feed)
return {
"id": db_feed.id,
"title": db_feed.title,
"content": db_feed.content,
"author_email": db_feed.author_email,
"author_nickname": author_nickname,
"image_urls": db_feed.image_urls,
}
def get_feed_by_id(db: Session, feed_id: int):
feed_data = (
db.query(Feed, User.nickname)
.join(User, User.email == Feed.author_email)
.filter(Feed.id == feed_id)
.first()
)
if feed_data is None:
raise HTTPException(status_code=404, detail="Feed not found")
feed, nickname = feed_data
return {
"id": feed.id,
"title": feed.title,
"content": feed.content,
"author_email": feed.author_email,
"author_nickname": nickname,
"image_urls": feed.image_urls,
}
def get_feeds(db: Session):
feeds = db.query(Feed, User.nickname).join(User, User.email == Feed.author_email).all()
feed_responses = []
for feed, nickname in feeds:
feed_dict = {
"id": feed.id,
"title": feed.title,
"content": feed.content,
"author_email": feed.author_email,
"author_nickname": nickname,
"image_urls": feed.image_urls,
}
feed_responses.append(feed_dict)
return feed_responses
def update_feed(
db: Session,
feed_id: int,
feed_update: FeedUpdate,
email: str,
new_images: Optional[List[UploadFile]] = None,
target_image_urls: Optional[List[str]] = None,
):
db_feed = db.query(Feed).filter(Feed.id == feed_id).first()
if db_feed is None:
raise HTTPException(status_code=404, detail="Feed Not Found")
if db_feed.author_email != email:
raise HTTPException(status_code=403, detail="Permission Denied")
author = db.query(User).filter(User.email == email).first()
author_nickname = author.nickname
db_feed.title = feed_update.title
db_feed.content = feed_update.content
existing_image_urls = db_feed.image_urls or []
# Case 1: Both new_images and target_image_urls exist
if new_images and target_image_urls:
for url in target_image_urls:
print(url)
delete_image_from_s3(url)
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]
existing_image_urls = existing_image_urls + new_image_urls
# Case 2: Only new_images exist
elif new_images:
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = existing_image_urls + new_image_urls
# Case 3: Only target_image_urls exist
elif target_image_urls:
for url in target_image_urls:
delete_image_from_s3(url)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]
db_feed.image_urls = existing_image_urls
print(db_feed.image_urls)
db.commit()
db.refresh(db_feed)
result = {
"id": db_feed.id,
"title": db_feed.title,
"content": db_feed.content,
"author_email": db_feed.author_email,
"author_nickname": author_nickname,
"image_urls": db_feed.image_urls,
}
logging.debug(f"Updated feed: {result}")
return result
def delete_feed(db: Session, feed_id: int, email: str):
db_feed = db.query(Feed).filter(Feed.id == feed_id).first()
if db_feed is None:
raise HTTPException(status_code=404, detail="Feed Not Found")
if db_feed.author_email != email:
raise HTTPException(status_code=403, detail="Permission Denied")
image_urls = db_feed.image_urls
for image_url in image_urls:
delete_image_from_s3(image_url)
db.delete(db_feed)
db.commit()
def upload_image_to_s3(images: List[UploadFile]):
image_urls = []
for image in images:
logging.debug(f"Uploading {image.filename}")
image_name = f"{uuid.uuid4()}.png"
s3_client.upload_fileobj(
image.file,
settings.S3_BUCKET,
image_name,
ExtraArgs={"ContentType": image.content_type},
)
image_url = f"https://{settings.S3_BUCKET}.s3.ap-northeast-2.amazonaws.com/{image_name}"
image_urls.append(image_url)
return image_urls
def delete_image_from_s3(image_url: str):
image_name = image_url.split("/")[-1]
bucket_name = settings.S3_BUCKET
logging.debug(f"Deleting from Bucket: {bucket_name}, Key: {image_name}")
s3_client.delete_object(Bucket=settings.S3_BUCKET, Key=image_name)비즈니스 로직을 전부 처리해야 해서 코드가 길지만, 뜯어보면 별 거 없다.
하나씩 살펴보자.
def upload_image_to_s3(images: List[UploadFile]):
image_urls = []
for image in images:
logging.debug(f"Uploading {image.filename}")
image_name = f"{uuid.uuid4()}.png"
s3_client.upload_fileobj(
image.file,
settings.S3_BUCKET,
image_name,
ExtraArgs={"ContentType": image.content_type},
)
image_url = f"https://{settings.S3_BUCKET}.s3.ap-northeast-2.amazonaws.com/{image_name}"
image_urls.append(image_url)
return image_urls먼저 코드 아래쪽에 이미지 업로드 로직을 추가한다.
해당 함수는 List[UploadFile]타입의 매개변수를 받는데, 이 타입에 대해 잠시 짚고 넘어가자.
List[UploadFile]
List[UploadFile]는 FastAPI에서 제공하는, 파일 업로드를 위해 사용되는 데이터 타입이다.
List에서 볼 수 있듯이 하나 이상의 UploadFile 객체를 리스트로 받을 수 있게 해 준다.
주요 속성 및 메서드는 다음과 같다.
- filename: 업로드된 파일의 이름
- content-type: 파일의 Content-Type. 예를 들어 image/png 등이 있다.
- file: 파일의 바이트 데이터를 읽을 수 있다.
- multiple: 한 번에 여러 개의 파일을 업로드할 수 있는 설정이다.
계속해서 코드를 보면,
image_urls = []먼저 업로드된 이미지 URL을 저장해 반환할 빈 리스트를 생성한다.
for image in images:
logging.debug(f"Uploading {image.filename}")
image_name = f"{uuid.uuid4()}.png"계속해서 주어진 모든 이미지에 대해 반복문을 돌며 처리할 로직을 작성한다.
가장 먼저 uuid를 사용해 겹치지 않는 이름을 생성한다.
s3_client.upload_fileobj(
image.file,
settings.S3_BUCKET,
image_name,
ExtraArgs={"ContentType": image.content_type},
)계속해서 boto3의 S3 클라이언트를 사용해 이미지파일을 업로드한다. 각 매개변수는 다음과 같다.
- image.file: 업로드할 파일 객체
- settings.S3_BUCKET: 업로드할 S3 버킷의 이름
- image_name: S3에 저장할 이미지 파일 이름
- ExtraArgs: 추가적인 메타데이터. 여기서는 ContentType만 작성했다.
image_url = f"https://{settings.S3_BUCKET}.s3.ap-northeast-2.amazonaws.com/{image_name}"
image_urls.append(image_url)
return image_urls마지막으로 업로드된 이미지 URL을 생성하고 초기화해 둔 리스트에 추가한다.
반복문이 끝나면, 그러니까 모든 이미지가 업로드되고 나면 image_urls를 반환한다.
def delete_image_from_s3(image_url: str):
image_name = image_url.split("/")[-1]
bucket_name = settings.S3_BUCKET
logging.debug(f"Deleting from Bucket: {bucket_name}, Key: {image_name}")
s3_client.delete_object(Bucket=settings.S3_BUCKET, Key=image_name)다음으로는 이미지 삭제 함수이다. 이미지 주소를 매개변수로 받는다.
image_name = image_url.split("/")[-1]먼저 이미지 URL에서 파일의 이름을 추출한다.
bucket_name = settings.S3_BUCKET버킷의 이름은 settings에 설정한 값을 읽어온다.
logging.debug(f"Deleting from Bucket: {bucket_name}, Key: {image_name}")
s3_client.delete_object(Bucket=settings.S3_BUCKET, Key=image_name)boto3의 delete_object 메서드를 사용해서 지정한 버킷의 해당 키(파일 이름)를 가진 객체를 삭제한다.
계속해서 피드 CRUD 로직의 변화를 보자.
def create_feed(db: Session, feed: FeedCreate, author_email: str, images: List[UploadFile] = None):
feed_dict = feed.model_dump()
feed_dict["author_email"] = author_email
if images:
image_urls = upload_image_to_s3(images)
feed_dict["image_urls"] = image_urls
author = db.query(User).filter(User.email == author_email).first()
if author is None:
raise HTTPException(status_code=404, detail="Author Not Found")
author_nickname = author.nickname
db_feed = Feed(**feed_dict)
db.add(db_feed)
db.commit()
db.refresh(db_feed)
return {
"id": db_feed.id,
"title": db_feed.title,
"content": db_feed.content,
"author_email": db_feed.author_email,
"author_nickname": author_nickname,
"image_urls": db_feed.image_urls,
}놀랍게도 변한 것이 거의 없다.
이미지를 추가 매개변수로 받고 이미지가 있는 경우 위에서 작성한 업로드 로직을 호출해 URL 리스트를 받는다.
if images:
image_urls = upload_image_to_s3(images)
feed_dict["image_urls"] = image_urls그리고 feed_dict에 image_urls를 추가해 받은 URL을 저장하고,
그대로 디비에 넣어준 뒤 반환값에도 image_urls를 넣어주면 끝이다.
이미지가 없다면 기존 로직은 그대로 진행하되 마지막 url 반환은 빈 리스트로 가게 될 것이다.
def get_feed_by_id(db: Session, feed_id: int):
feed_data = (
db.query(Feed, User.nickname)
.join(User, User.email == Feed.author_email)
.filter(Feed.id == feed_id)
.first()
)
if feed_data is None:
raise HTTPException(status_code=404, detail="Feed not found")
feed, nickname = feed_data
return {
"id": feed.id,
"title": feed.title,
"content": feed.content,
"author_email": feed.author_email,
"author_nickname": nickname,
"image_urls": feed.image_urls,
}다음으로는 조회 로직이다.
image_urls를 추가하고 결괏값을 바로 리턴하는 것 외에는 변한 것이 없다.
def get_feeds(db: Session):
feeds = db.query(Feed, User.nickname).join(User, User.email == Feed.author_email).all()
feed_responses = []
for feed, nickname in feeds:
feed_dict = {
"id": feed.id,
"title": feed.title,
"content": feed.content,
"author_email": feed.author_email,
"author_nickname": nickname,
"image_urls": feed.image_urls,
}
feed_responses.append(feed_dict)
return feed_responses전체 조회도 마찬가지이다.
def update_feed(
db: Session,
feed_id: int,
feed_update: FeedUpdate,
email: str,
new_images: Optional[List[UploadFile]] = None,
target_image_urls: Optional[List[str]] = None,
):
db_feed = db.query(Feed).filter(Feed.id == feed_id).first()
if db_feed is None:
raise HTTPException(status_code=404, detail="Feed Not Found")
if db_feed.author_email != email:
raise HTTPException(status_code=403, detail="Permission Denied")
author = db.query(User).filter(User.email == email).first()
author_nickname = author.nickname
db_feed.title = feed_update.title
db_feed.content = feed_update.content
existing_image_urls = db_feed.image_urls or []
# Case 1: Both new_images and target_image_urls exist
if new_images and target_image_urls:
for url in target_image_urls:
print(url)
delete_image_from_s3(url)
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]
existing_image_urls = existing_image_urls + new_image_urls
# Case 2: Only new_images exist
elif new_images:
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = existing_image_urls + new_image_urls
# Case 3: Only target_image_urls exist
elif target_image_urls:
for url in target_image_urls:
delete_image_from_s3(url)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]
db_feed.image_urls = existing_image_urls
print(db_feed.image_urls)
db.commit()
db.refresh(db_feed)
result = {
"id": db_feed.id,
"title": db_feed.title,
"content": db_feed.content,
"author_email": db_feed.author_email,
"author_nickname": author_nickname,
"image_urls": db_feed.image_urls,
}
logging.debug(f"Updated feed: {result}")
return result다만 피드 수정 로직은 복잡도가 꽤 올라가는데,
이는 피드에 사진을 여러 장 올릴 수 있게 허용했기 때문에 발생한 일이다.
def update_feed(
db: Session,
feed_id: int,
feed_update: FeedUpdate,
email: str,
new_images: Optional[List[UploadFile]] = None,
target_image_urls: Optional[List[str]] = None,
):먼저 매개변수에 new_images와 target_image_urls가 추가로 생겼다.
여기서 new_images는 물론 새로 추가되는 이미지이고, target_image_urls는 삭제될 사진의 URL이다.
이미지 로직 이전 코드의 설명은 지난 글에 있으니 바로 건너뛰자.
existing_image_urls = db_feed.image_urls or []먼저 기존 image_url을 가져온다.
# Case 1: Both new_images and target_image_urls exist
if new_images and target_image_urls:
for url in target_image_urls:
print(url)
delete_image_from_s3(url)
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]
existing_image_urls = existing_image_urls + new_image_urls
# Case 2: Only new_images exist
elif new_images:
new_image_urls = upload_image_to_s3(new_images)
existing_image_urls = existing_image_urls + new_image_urls
# Case 3: Only target_image_urls exist
elif target_image_urls:
for url in target_image_urls:
delete_image_from_s3(url)
existing_image_urls = [url for url in existing_image_urls if url not in target_image_urls]이후엔 다음의 세 가지 케이스에 따라 이미지를 삭제/추가한다.
- 새 이미지와 삭제할 이미지가 둘 다 있을 경우 - 새 이미지를 추가하고 기존 이미지를 삭제한다.
- 새 이미지만 있을 경우 - 기존 사진에 새 이미지를 더한다.
- target_image만 있을 경우 - 해당 이미지를 삭제한다.
코드가 길어 보일 수도 있지만, 설명에 쓰인 그대로의 로직뿐이라 당황할 필요는 없다.
db.commit()
db.refresh(db_feed)
result = {
"id": db_feed.id,
"title": db_feed.title,
"content": db_feed.content,
"author_email": db_feed.author_email,
"author_nickname": author_nickname,
"image_urls": db_feed.image_urls,
}
logging.debug(f"Updated feed: {result}")
return result마지막으로 디비에 반영한 뒤,
업데이트된 feed 객체를 바탕으로 반환값을 만들어 리턴한다.
def delete_feed(db: Session, feed_id: int, email: str):
db_feed = db.query(Feed).filter(Feed.id == feed_id).first()
if db_feed is None:
raise HTTPException(status_code=404, detail="Feed Not Found")
if db_feed.author_email != email:
raise HTTPException(status_code=403, detail="Permission Denied")
image_urls = db_feed.image_urls
for image_url in image_urls:
delete_image_from_s3(image_url)
db.delete(db_feed)
db.commit()피드 삭제 로직이다.
여기도 기존 이미지 url을 가져온 뒤, 피드 삭제 전에 먼저 삭제해 준다.
feed_router.py
마지막으로 위 서비스로직을 호출해 사용하는 라우팅 함수를 살펴보자.
from fastapi import APIRouter, Depends, HTTPException, UploadFile, File, Form
from sqlalchemy.orm import Session
from models.feed import FeedCreate, FeedResponse, FeedUpdate
from services import feed_service, auth_service
from config.db import get_db
from typing import List
import logging
# logging.basicConfig(level=logging.DEBUG)
router = APIRouter()
@router.post("/create", response_model=FeedResponse)
def create(
title: str = Form(...),
content: str = Form(...),
images: List[UploadFile] = File(None),
db: Session = Depends(get_db),
email: str = Depends(auth_service.get_current_user_authorization),
):
if email is None:
raise HTTPException(status_code=401, detail="Not authorized")
feed = FeedCreate(title=title, content=content)
return feed_service.create_feed(db, feed, email, images)
@router.get("/read/{feed_id}", response_model=FeedResponse)
def read_feed(feed_id: int, db: Session = Depends(get_db)):
return feed_service.get_feed_by_id(db, feed_id)
@router.get("/list", response_model=List[FeedResponse])
def list_feeds(db: Session = Depends(get_db)):
return feed_service.get_feeds(db)
@router.patch("/update/{feed_id}", response_model=FeedResponse)
def update(
feed_id: int,
title: str = Form(...),
content: str = Form(...),
new_images: List[UploadFile] = File(None),
target_image_urls: List[str] = Form(None),
db: Session = Depends(get_db),
email: str = Depends(auth_service.get_current_user_authorization),
):
if email is None:
raise HTTPException(status_code=401, detail="Not authorized")
feed_update = FeedUpdate(title=title, content=content)
updated_feed = feed_service.update_feed(
db, feed_id, feed_update, email, new_images=new_images, target_image_urls=target_image_urls
)
return updated_feed
@router.delete("/delete/{feed_id}", response_model=None)
def delete(
feed_id: int,
db: Session = Depends(get_db),
email: str = Depends(auth_service.get_current_user_authorization),
):
if email is None:
raise HTTPException(status_code=401, detail="Not Authorized")
feed_service.delete_feed(db, feed_id, email)바뀐 부분이 많지는 않다. 위에서부터 살펴보자.
@router.post("/create", response_model=FeedResponse)
def create(
title: str = Form(...),
content: str = Form(...),
images: List[UploadFile] = File(None),
db: Session = Depends(get_db),
email: str = Depends(auth_service.get_current_user_authorization),
):
if email is None:
raise HTTPException(status_code=401, detail="Not authorized")
feed = FeedCreate(title=title, content=content)
return feed_service.create_feed(db, feed, email, images)먼저 피드 생성의 경우, 텍스트와 파일을 같이 올리기 위해 매개변수 타입이 바뀌었는데,
구체적으로는 타이틀과 컨텐츠 역시 form 데이터로 받은 후에 따로 객체를 생성하도록 수정했다.
images라는 이름으로는 복수의 이미지를 올릴 수 있게 구현했다.
그런 다음 위에서 구성한 서비스 로직을 호출해 그 결과를 리턴한다.
@router.patch("/update/{feed_id}", response_model=FeedResponse)
def update(
feed_id: int,
title: str = Form(...),
content: str = Form(...),
new_images: List[UploadFile] = File(None),
target_image_urls: List[str] = Form(None),
db: Session = Depends(get_db),
email: str = Depends(auth_service.get_current_user_authorization),
):
if email is None:
raise HTTPException(status_code=401, detail="Not authorized")
feed_update = FeedUpdate(title=title, content=content)
updated_feed = feed_service.update_feed(
db, feed_id, feed_update, email, new_images=new_images, target_image_urls=target_image_urls
)
return updated_feed여기도 크게 다르지 않다.
모양이 위와 조금 다른 이유는 개발 중 로깅을 위해 결괏값 생성과 반환을 분리했기 때문이다.
다음 글에서는 아마도 수정할 예정이지만, 지금은 일단 그대로 둔다.
나머지 로직은 바뀐 것이 없다.
Summary
이렇게 해서 텍스트만 올릴 수 있던 게시글에 복수의 이미지를 올리는 부분을 구현했다.
다만 현재 내 로컬에서는 알 수 없는 정책오류 탓에 삭제가 제대로 이루어지지 않고 있으며,
아무래도 레퍼런스가 적어 구현에 오랜 시간이 걸렸다.
현재 내가 겪고 있는 AWS 정책 오류가 코드 레벨에 의한 것이라면 바로 수정을 해놓도록 하겠다.
또한 코드가 일관성이 살짝 떨어지고 정리가 덜 된 느낌이 있는데,
이는 내가 이리저리 코드를 돌려본 흔적이라, 이후의 개발에서 리팩터링 하며 지나갈 예정이다.
이미지 업로드를 구현했으니 다음은 무엇을 구현할지 조금 더 생각해 본 다음에..
일단 이 글은 여기서 끝!
'Python > FastAPI' 카테고리의 다른 글
- Total
- Today
- Yesterday
- 중남미
- 야경
- 스프링
- 알고리즘
- 지지
- Algorithm
- 세계일주
- 면접 준비
- 자바
- 스트림
- BOJ
- 동적계획법
- 맛집
- a6000
- 백준
- 남미
- 여행
- java
- 세모
- Backjoon
- Python
- 리스트
- 유럽
- 유럽여행
- 칼이사
- spring
- 파이썬
- 세계여행
- RX100M5
- 기술면접
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |