
티스토리 뷰
[면접 준비 - Java]Data Structures in a Nutshell
Vagabund.Gni 2022. 12. 17. 18:37목차
스택, 큐, 트리, 그래프에 대해선 지난번에 짧게 요약했다.
이번 글에선 자료구조 중 배열 + 컬렉션 프레임워크에 대해 가능한 짧게 요약한다.
Array
배열은 한 마디로 말하면 같은 자료형과 길이가 정해진 행렬이라고 할 수 있다.
행렬이기 때문에 인덱스가 정의되어 있고, 메모리를 연속으로 사용할 것을 요구하기 때문에
각각의 값은 변경할 수 있으나 한 번 정해진 크기는 바꿀 수 없다.
또한 엄밀하게 말하면 자바의 배열은 기본적으로 제공하는 자료형이기 때문에 다양한 관련 함수가 정의되어 있으며,
별도의 호출 없이 손쉽게 정의할 수 있다.
배열은 자료형인가?
결론부터 말하자면 자바에서 배열은 자료형이며 동시에 자료구조로도 분류할 수 있다.
자료형은 변수의 타입을 가리키는 단어이며,
자료구조는 데이터의 집합을 가리키는 단어이기 때문이다.
배열은 자바에서 기본적으로 변수이면서도 데이터의 집합이므로
자료형이자 가장 단순한 자료구조라고 보는 것이 맞다.
Data Structure
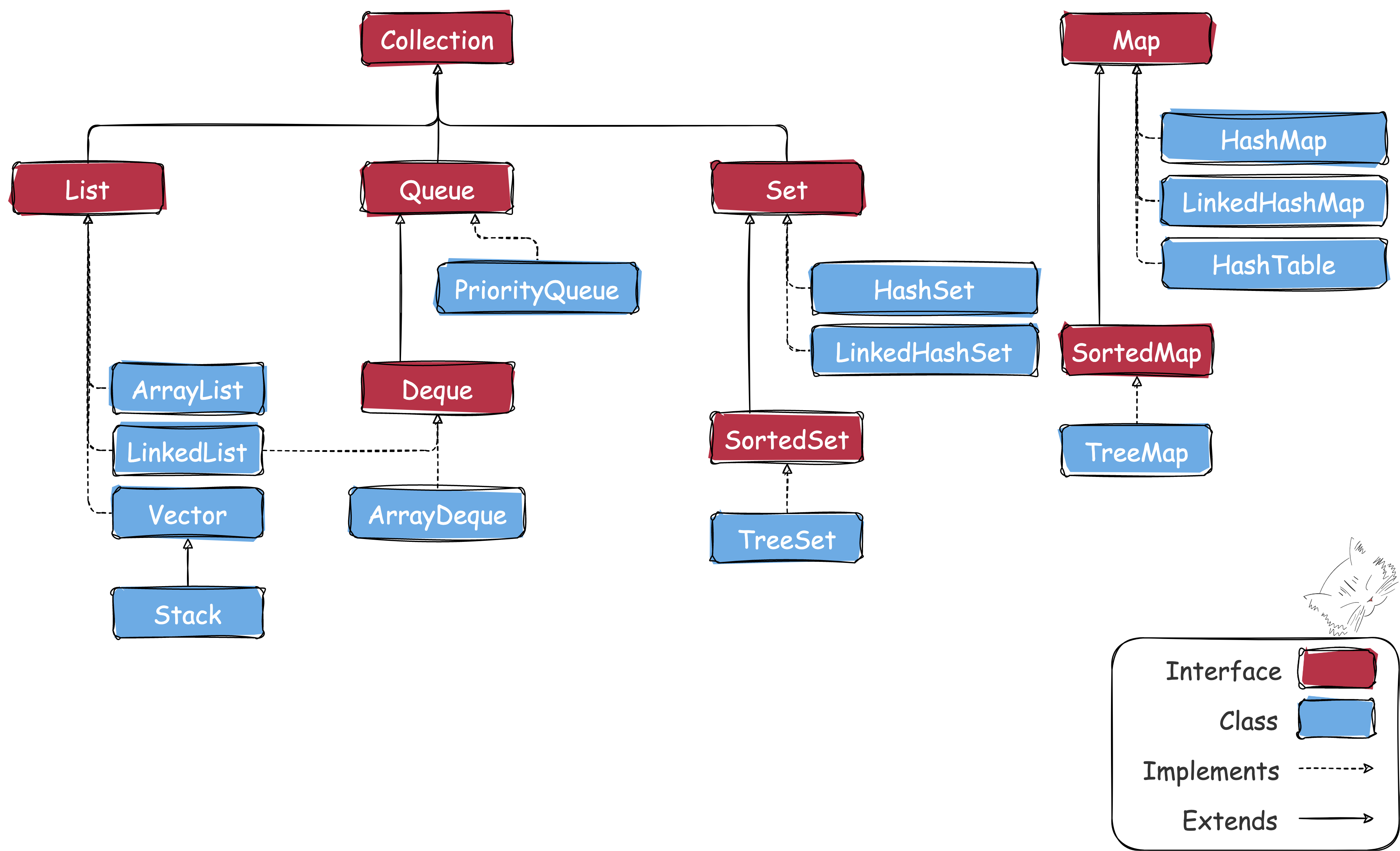
자바의 자료구조는 크게 Collection과 Map으로 나눌 수 있다.
조금 더 세분화하면 대략 아래와 같은 구성을 이루고 있으며,
- List - ArrayList, LinkedList, Vector, Stack
- Set - HashSet, LinkedHashSet, TreeSet
- Queue - PriorityQueue, ArrayDeque
- Map - HashMap, LinkedHashMap, Hashtable, TreeMap
큐를 제외한 나머지 세 인터페이스의 차이를 보면 대략 아래와 같다.
| 인터페이스 | 차이점 |
| List<E> | 순서(인덱스)가 있다. 데이터의 중복을 허용한다. |
| Set<E> | 순서가 없다. 데이터의 중복을 허용하지 않는다. |
| Map<K, V> | 키-값으로 이루어지며 순서가 없다. 키는 중복을 허용하지 않지만 값은 중복될 수 있다. |
하나씩 빠르게 정리하자.
List<E>
리스트는 데이터의 순서가 유지되며, 원소의 중복 저장이 가능한 자료구조이다.
ArrayList<E>
가장 많이 사용되는 클래스. 내부적으로 배열을 이용하며 인덱스를 사용, 데이터의 순서가 유지된다.
하지만 크기가 고정된 배열과는 달리 ArrayList는 크기가 고정되지 않는다, 즉 연속된 메모리를 요구하지 않는다.
특정 인덱스의 삽입/삭제 시 나머지 인덱스가 전부 앞당겨지거나 밀리는 특징이 있으며,
빈번한 삽입/삭제에는 LinkedList가 좀 더 낫다.
LinkedList<E>

배열 사용의 단점을 극복하기 위한 리스트이다. 효율적인 삽입/삭제를 위해
데이터가 불연속적으로 존재하며, 그 사이에 링크를 걸어 자료구조를 구성한다.
모든 노드는 데이터와 함께 이전/이후 데이터의 주소 값을 가지고 있으며, 삽입/삭제 시 인덱스의 이동이 아닌
링크의 생성/삭제로 처리한다. 사용법은 ArrayList와 비슷하다.
ArrayList<E> vs. LinkedList<E>
| ArrayList<E> | LinkedList<E> | |
| Pros | 데이터를 순차적으로 삽입/삭제하는 경우 데이터를 읽어들이는 경우 데이터의 개수가 자주 변하지 않는 경우 |
중간에 데이터를 추가하거나 삭제해야 할 경우 데이터의 개수가 자주 변하는 경우 |
| Cons | 중간에 데이터를 삽입/삭제하는 경우 | 데이터를 읽어들이는 경우 |
Vector<E>
ArrayList와 마찬가지로 내부적으로 배열을 이용하는 리스트이다.
차이점은 아래와 같다.
- Thread-Safe(여러 스레드로부터 동시에 접근이 이루어져도 실행에 문제가 없음) 하며 동기화 지원, 멀티스레드 환경에 최적
- 한 번에 하나의 스레드만 접근이 가능하다.
- 각종 메서드에 synchronized가 걸려 있어 스레드마다 락이 걸리기 때문에 ArrayList에 비해 느리다.
참고로 리스트, 셋, 맵 전부 synchronizedXXX() 메서드를 지원하기 때문에
멀티스레드 환경에선 벡터보단 이 메서드를 사용해 자료구조를 만들어 사용한다.
Stack<E>
Vector<E>를 상속받는 클래스이다. 후입 선출 구조를 가지고 있으며 push(), pop()이라는 개별 메서드를 사용한다.
자세한 건 따로 정리했으니 생략.
Set<E>
셋은 말 그대로 집합이다. 데이터의 순서가 유지되지 않으며 중복 데이터도 허용하지 않는다.
내부적으로 모두 Map으로 구현된다는 특징이 있다.
HashSet<E>
셋 클래스 중에 가장 많이 사용된다. 내부적으로 HashMap을 사용하여 데이터를 저장하며
해시 알고리즘을 사용해 정렬 없이도 검색/삽입이 매우 빠르다는 특징이 있다.
조금 구체적으로는 해시 코드를 내부적으로 인덱스로 활용해 버킷에 담는 식이다.
당연하게도 인덱스를 사용한 개별 출력은 불가능하며, 전체 출력만 가능하다.
Hash
비밀번호 암호화에 쓰이는 그 해시이다. 다만 색인을 위해 단순한 알고리즘을 가지고 있으며,
임의의 길이에 대해 고정된 결과를 매핑하는 해시함수의 특성을 이용해 빠른 색인이 가능해진다.
참고로 매핑 전의 데이터를 키, 매핑 후의 데이터를 해시 코드, 이 과정을 해싱이라 부른다.
해시함수의 특성상 충돌(다른 키에 대해 동일한 해시코드 매핑)이 발생할 가능성이 있으며
이를 피하기 위해 해당 해시 코드에 데이터가 존재하는 경우 그 뒤에 노드를 추가해 LinkedList를 구성하거나(자바)
비어있는 다른 값에 넣어주는 오픈 어드레싱(선형, 2차, 2중 해싱) 방식을 사용한다.
당연하게도 수용률이 일정 비율을 넘어가면 성능이 급격하게 떨어지며, 해시 셋의 경우
데이터의 개수가 버킷 길이의 1.25배가 되었을 때를 기준으로 버킷의 길이를 두 배로 늘리도록 만들어져 있다.
다만 이는 새로운 인덱싱을 포함하기에 비용이 굉장히 많이 드는 작업이기 때문에
실시간으로 빠르게 작업해야 하는 경우 메모리를 소모해 점진적으로 옮기는 방법,
혹은 분산 환경에서 일관성을 유지하기 위해 해시의 비트를 1 증가시키고 저장공간을 두 배로 늘린 뒤
점진적으로 옮기는 Consistent Hashing 방법을 사용한다.
LinkedHashSet<E>
LinkedList + HashSet으로, 중복은 허용하지 않지만 순서를 가지는 셋이다.
입력된 순서대로 데이터를 관리하기 때문에 출력도 순서대로다.
TreeSet<E>
중복을 허용하지 않고, 순서를 가지지 않으나
내부적으로 이진 탐색 트리 형태로 데이터를 정렬해 저장한다(기본적으로 오름차순).
Queue<E>
큐에 대해서도 분리된 글이 있으므로 특징만 짚고 넘어간다.
PriorityQueue<E>
이름 그대로 설정된 우선순위(기본은 오름차순)로 데이터를 정렬해 보관하는 큐이다.
즉, 우선순위에 따라 반환 순서가 달라진다는 뜻이다.
내부적으로 힙 트리를 이용해 데이터를 정렬하며,
정렬 기준을 커스터마이징 할 수 있다.
ArrayDeque<E>
어레이덱은 이름처럼 양쪽에서 모두 삽입/반환이 가능한 큐이다(Double-Ended Queue).
스택으로 사용할 땐 스택보다, 큐로 사용할 땐 큐보다 빠르며 용량 제한이 없고,
보통 후입 선출 구조인 스택을 구현할 때 이 어레이덱을 활용한다.
스택이 있는데 왜? 이유는 아래와 같다.
- Vertor<E>를 상속받아 모든 메서드에 synchronized가 걸려있어 스레드에 락이 걸려 단일 스레드에서 불리
- 마찬가지 이유로 중간에서 데이터를 삽입/삭제하는 것이 불가능
- 객체 생성 시 초기 용량 설정 불가능
Map<K, V>
맵은 컬렉션을 상속받지 않으며, 조금 독특한 규칙을 지니고 있다.
키-값으로 이루어지며 순서가 없고, 키는 중복을 허용하지 않지만 값은 중복될 수 있다.
키와 값의 타입을 별개로 지정할 수 있으며, 기존의 키에 다른 값을 저장하면 값이 대체되는 특징이 있다.
HashMap<K, V>
가장 많이 사용되는 맵이다. 해시 셋과 비슷하게 해시 알고리즘을 이용해 값을 저장하며, 검색/삽입 속도가 매우 빠르다.
LinkedHashMap<K, V>
역시 LinkedList와 합쳐져 데이터의 삽입 순서를 지키는 특징이 있다.
HashTable<K, V>
Thread-Safe 한 해시 맵이라고 생각하면 된다.
TreeMap<K, V>
트리 셋과 비슷하게 이진트리를 기반으로 한 맵이다. 역시 자동으로 데이터를 정렬해 저장하는데,
데이터의 값만 저장하는 트리셋과 달리 트리 맵은 키, 그리고 값이 저장된 Map, Entity를 저장한다.
해시 알고리즘에 비해 속도는 느리지만 정렬된 데이터가 필요할 경우 사용한다.
'Development > Technical Interview' 카테고리의 다른 글
| [면접 준비 - CS]프로세스, 스레드, 동기화, 그리고 (6) | 2022.12.22 |
|---|---|
| [면접 준비 - CS]노드(Node)에 대하여 (3) | 2022.12.20 |
| [면접 준비 - Network]부하 분산(SLB), AWS ELB에 관하여 (3) | 2022.12.19 |
| [면접 준비 - Database]SQL Mapper, ORM (5) | 2022.12.16 |
| [면접 준비 - Network]SSR vs. CSR (1) | 2022.12.16 |
| [면접 준비 - Network]URI/URL/URN (1) | 2022.12.16 |
- Total
- Today
- Yesterday
- java
- 세계일주
- 유럽
- 남미
- Algorithm
- 지지
- spring
- 알고리즘
- 면접 준비
- 세계여행
- 세모
- 여행
- 자바
- 스프링
- 스트림
- Backjoon
- 맛집
- RX100M5
- 칼이사
- 리스트
- 파이썬
- 중남미
- a6000
- 백준
- 유럽여행
- 야경
- Python
- BOJ
- 기술면접
- 동적계획법
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |