
티스토리 뷰
개발에 발을 담그고 나서 배포는 설정싸움이라는 말을 자주 하는데,
도무지 엘라스틱 서치 설정이 내 맘대로 되지가 않아서 거치적거린다.
새로운 세계에 들어간다는 건 항상 단어공부와 인내심으로 이루어지는 것 같다.
머릿속에서 자꾸만 미끄러지는 새로운 단어도 외울 겸, 마주하고 있는 기술에 대해 요약하자.
시작하기 전에 말이 긴 건 조금 화가 나서 그렇다..
Lucene

아파치 루씬, 혹은 루씬은 아파치 재단의 후원하에 만들어지는 오픈소스&&고성능 검색 라이브러리 소프트웨어이다.
자바로 이루어져 있으나 다른 언어에서도 사용 가능하도록 변경되었으며, 라이브러리라는 말처럼
자체적으로 정보 수집 기능은 가지고 있지 않다.
또한 모든 응용프로그램에 적합하지만 특히 웹 검색과 로컬 사이트의 검색 구현에 유용하다고 한다.
루씬의 특징은 전문(Full Text) 검색을 위한 역색인(Inverted Index) 구조인데, 오늘의 첫 단어가 나왔다.
Inverted Index
역색인은 가장 직관적으로 표현하자면 Map에서 Key↔Value를 바꾼 것이다.
조금 수학으로 가자면 DB 테이블을 Transpose 한 거라고 생각해도 된다.
더 현실적으로 말하자면 대략 아래와 같이 나타낼 수 있는데,
사실 별 거 아니고 책 앞의 목차와 뒤의 색인의 관계라고 생각하면 된다.
어쨌거나 역색인을 바탕으로 루씬은 크게 두 가지 단계로 나뉜 작업을 진행하는데, 대략 아래와 같다.
- 분석
- 외부에서 텍스트 자료를 입력받는다.
- 루씬에서 사용하는 개별 단위인 문서를 생성한다. 문서는 여러개의 필드로 이루어져 있다.
- 문서를 분석해 토큰이라는 단위로 분리한다. 각종 언어의 분석기를 지원한다.
- 분석이 끝난 문서를 토큰 색인에 추가한다.
- 검색
- 검색어를 입력받는다.
- 입력받은 검색어를 검색 엔진이 인식할 수 있는 Query 객체로 전환한다.
- 순수 불리언 모델(검색어 유무 판별)과 벡터 공간 모델(연관도와 유사도 점수화)을 이용해 검색한다.
둘 중 어떤 모델을 사용할지 선택할 수 있다.
Elasticsearch
어째서인지 띄어쓰기를 해야할 것만 같은 엘라스틱 서치는 루씬을 기반으로 개발된 검색 엔진이다.
역시 자바로 이루어져 있으며, 스키마에서 자유로운 JSON을 이용해 데이터를 주고받는다.
DB로 사용하는 것도 가능하다고는 하던데, 아직 나는 잘 모르겠고 여기서부터 새로운 단어가 쏟아진다.
기존에 익숙하게 사용했던 관계형 데이터베이스의 언어로 번역해 보자.
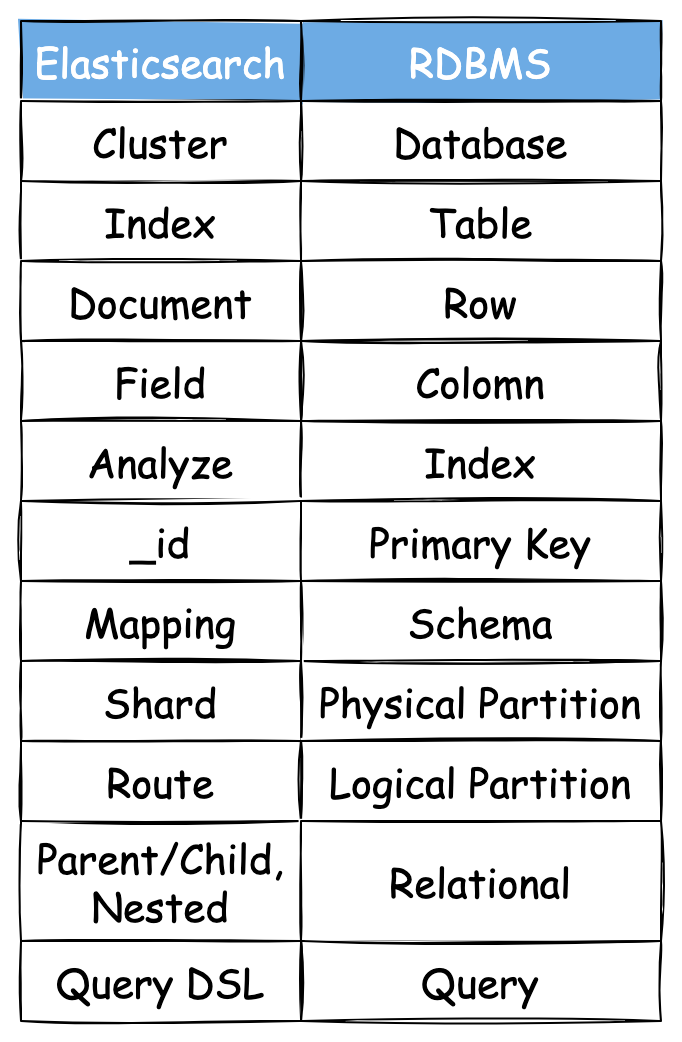
행과 열로 이루어진 자료구조가 아닌 위에 말했듯 JSON으로 직렬화된 복잡한 구조를 저장하기 때문에
사용하는 어휘가 이렇게 다르다고 한다.
물론 위와 같은 매칭이 정확하게 1:1로 들어맞는 것은 아니다! 그랬다면 굳이 다른 단어를 쓸 필요가 없었을 테니까.
RDB에 익숙한 나 같은 사람이 개념을 대략이나마 유추할 수 있도록 도와주는 기본 사전 정도에 가깝다고 할 수 있다.
추가로 CRUD에 쓰이는 언어도 다른데, 이 역시 아래와 같다.

계속해서 구조에 대한 단어만 배우면 이제 대충 진입 준비는 끝난다.
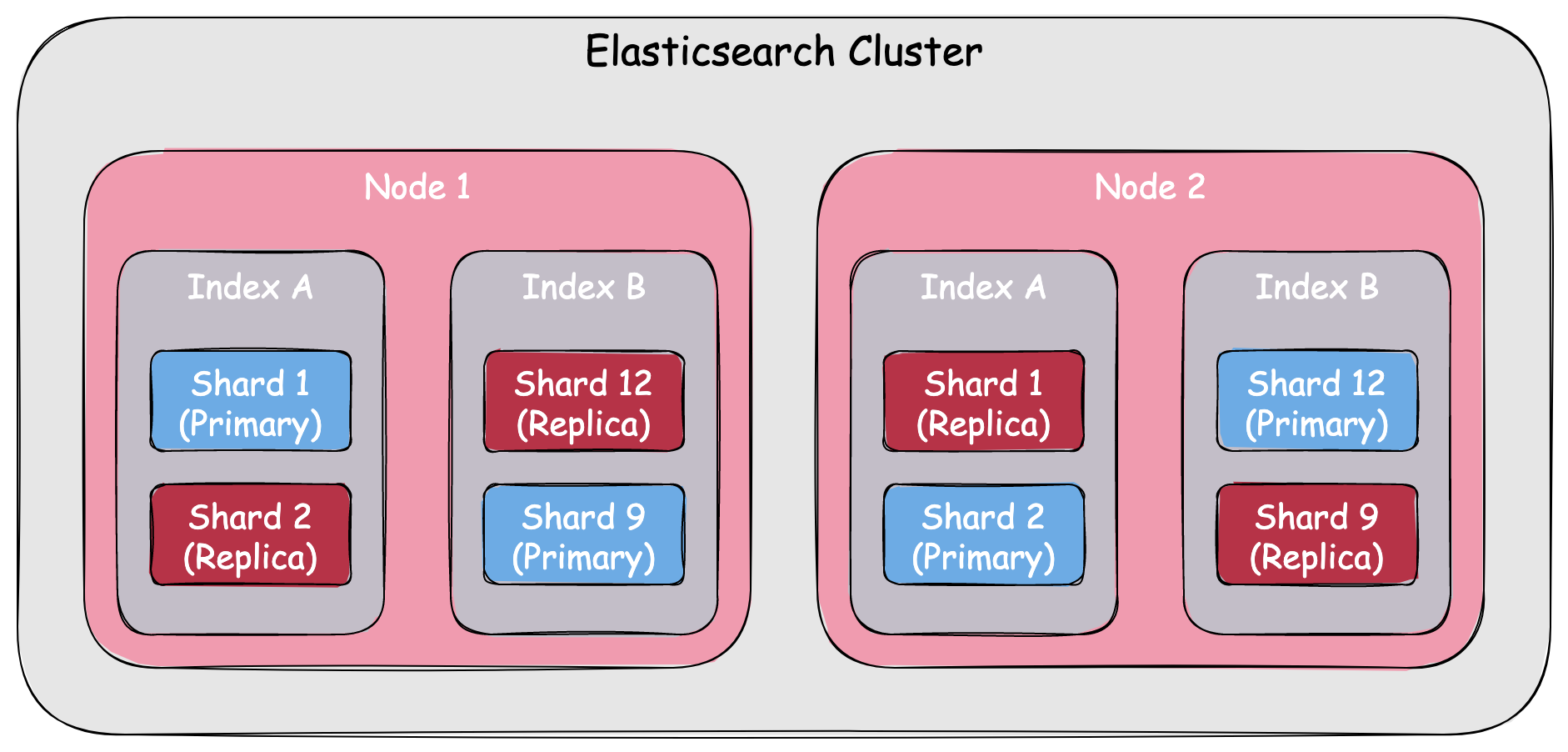
- Cluster
- 하나 이상의 노드로 이루어진 집합
- 서로 다른 클러스터는 독립적으로 유지(데이터 접근 및 교환 불가)
- 여러 대의 서버로 하나의 클러스터를 구성하거나 그 반대도 가능
- Node
- Elasticsearch의 단위 프로세스. 아래와 같은 다양한 역할로 분류된다.
- 대규모 클러스터에서 로드밸런서 역할
- 데이터 사전 처리 파이프라인 역할
- 색인이 끝난 데이터 CRUD 역할
- 전체 클러스터를 제어하는 마스터 역할(인덱스 생성, 삭제, 샤딩 조정)
- Shard
- 데이터의 분산저장 단위. Scale-out을 위해 하나의 Index를 여러 Shard로 쪼개 저장.
- 검색 성능 향상을 위해 개수 조정 가능
- Replica
- Shard의 한 종류. 이름 그대로 데이터 정합성을 위해 복제한 Shard이다.
- 같은 이유 때문에 Replica는 서로 다는 노드에 위치시켜야 함
ELK Stack
ELK스택은 Elasticsearch + Logstash + Kibana에서 앞글자를 따온 기술스택을 말하며,
공식적으로 같은 버전으로 동시에 업데이트가 이루어지는 소프트웨어 묶음이다.
여기에 최근에 나온 Filebeat까지 포함해 Elastic Stack이라고 부르기도 한다.
각각의 역할은 대략 아래와 같다.
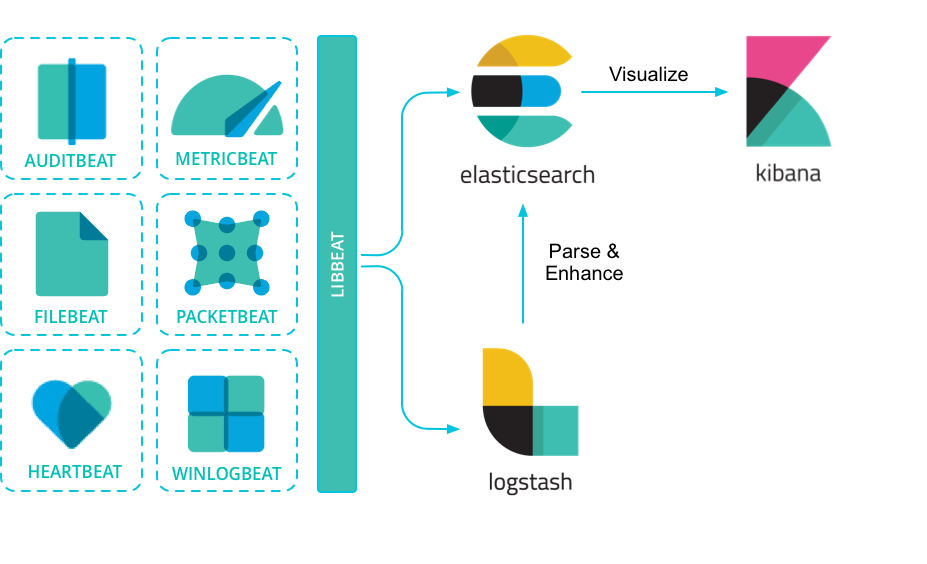
출처: https://www.elastic.co/guide/en/beats/libbeat/7.16/beats-reference.html
What are Beats? | Beats Platform Reference [7.16] | Elastic
Beats are open source data shippers that you install as agents on your servers to send operational data to Elasticsearch. Elastic provides Beats for capturing: Beats can send data directly to Elasticsearch or via Logstash, where you can further process and
www.elastic.co
- Logstash - 데이터 수집 후 변환하여 Elasticsearch로 전송
- Kibana - Elasticsearch의 데이터에 대한 분석 및 시각화
- Filebeats - Logstash보다 경량화된 데이터 수집기. 여러 노드에서 데이터를 모아 Logstash와 Elasticsearch로 전송
pros and cons
오늘은 Elasticsearch의 개괄만 적기로 했으니 이 정도까지만 알아보고 장단점과 함께 끝을 맺자.
글을 쓰는 지금 시점에선 이틀 정도 사투를 벌인 끝에 어느 정도 설정이 끝나 있는 상태이다.
같은 시간낭비를 줄이기 위해 빨리 다음 글을 적는 것으로...
pros
- Scale-out: 위에서 봤듯이 샤드와 노드 등을 통해 수평 확장이 용이하다.
- 안정성: 레플리카 샤드를 통해 데이터의 안정성과 정합성을 보장한다.
- Schemaless: 형태가 정해지지 않은 JSON 기반의 엔진으로 검색과 색인이 편하다.
- RESTful API: HTTP 기반의 RESTful API를 활용하며 역시 JSON을 사용해 언어, OS, 시스템에서 자유롭다.
- Multi-Tenency: 다른 인덱스라도 같은 필드명을 포함한다면 한 번에 조회할 수 있다.
- 전문(Full-text) 검색 & 역색인: 내용 전체를 색인, 특정 필드가 포함된 문서를 조회할 수 있다. 언어별 플러그인도 존재한다.
cons
- 시간 지연: 색인된 데이터가 검색될 때까지 1초 정도 시간 지연이 발생한다. 내부 과정이 복잡하기 때문.
- 트랜잭션 미지원: 성능 향상을 위해 트랜잭션과 그게 포함된 롤백을 지원하지 않는다.
- 데이터 업데이트 불가: 데이터가 업데이트되면 아예 문서를 삭제한 뒤 새로 생성한다. 데이터 불변성을 확보하기 위함
'Development > Database' 카테고리의 다른 글
| [Database]Index에 대하여 + B-Tree (2) | 2023.03.20 |
|---|---|
| [Database]Inner Join, Outer Join, 그리고 (0) | 2023.03.16 |
| [Data]자바에도 있네, 데이터 분석 툴. Tablesaw (0) | 2023.02.17 |
| [Redis]레디스(Redis), 스프링부트에 캐싱 적용 (0) | 2023.01.19 |
| [Redis]레디스(Redis), StringRedisTemplate 튜토리얼 (2) | 2023.01.18 |
| [Redis]캐시(Cache), 그리고 레디스(Redis) (2) | 2023.01.14 |
- Total
- Today
- Yesterday
- RX100M5
- 리스트
- 유럽여행
- 기술면접
- 백준
- Python
- spring
- 칼이사
- 스트림
- BOJ
- 여행
- a6000
- 파이썬
- 야경
- 자바
- 세계여행
- 세모
- 동적계획법
- 맛집
- 알고리즘
- java
- 지지
- 스프링
- 유럽
- 남미
- 중남미
- 세계일주
- 면접 준비
- Algorithm
- Backjoon
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |