
티스토리 뷰
목차
서비스의 규모와 사용자가 증가해 한 대의 서버로는 트래픽을 감당할 수 없을 때,
보통은 비용이 많이 드는 수직적 확장(Scale-Up) 대신 수평적 확장(Scale-Out)을 선택한다.

이처럼 수평적으로 확장된 서버를 로드밸런스와 함께 사용하면 쉽게 서버의 부하를 분산시킬 수 있다.
하지만 이때 서버마다 사용하는 데이터베이스 역시 분산되면서 기존에는 존재하지 않았던 문제가 생기게 된다.
바로 세션을 사용하는 경우의 사용자 정보 및 요청 저장이 분산된다는 것인데,
예를 들면 A서버에 저장된 세션아이디를 가진 고객이 B서버로 요청을 했을 때 B서버는 세션 정보를 가지지 않기 때문에
사용자에게 새로운 자격증명, 즉 로그인 등을 요구하게 된다.
즉, 서버 사이의 데이터 정합성이 깨질 수 있다는 말이다.
조금 정확하게 짚고 넘어가자면, 예상할 수 있듯이 이는 세션을 제외한 다른 데이터에도 적용되는 문제다.
이어서 이 문제를 방지하는 방법에 대해 정리하자.
Stickly Session
Sticky Session이란 이름 그대로 하나의 세션은 하나의 서버에서 독점적으로 처리하도록 하는 방식이다.
그림으로 보면 아래와 같다.
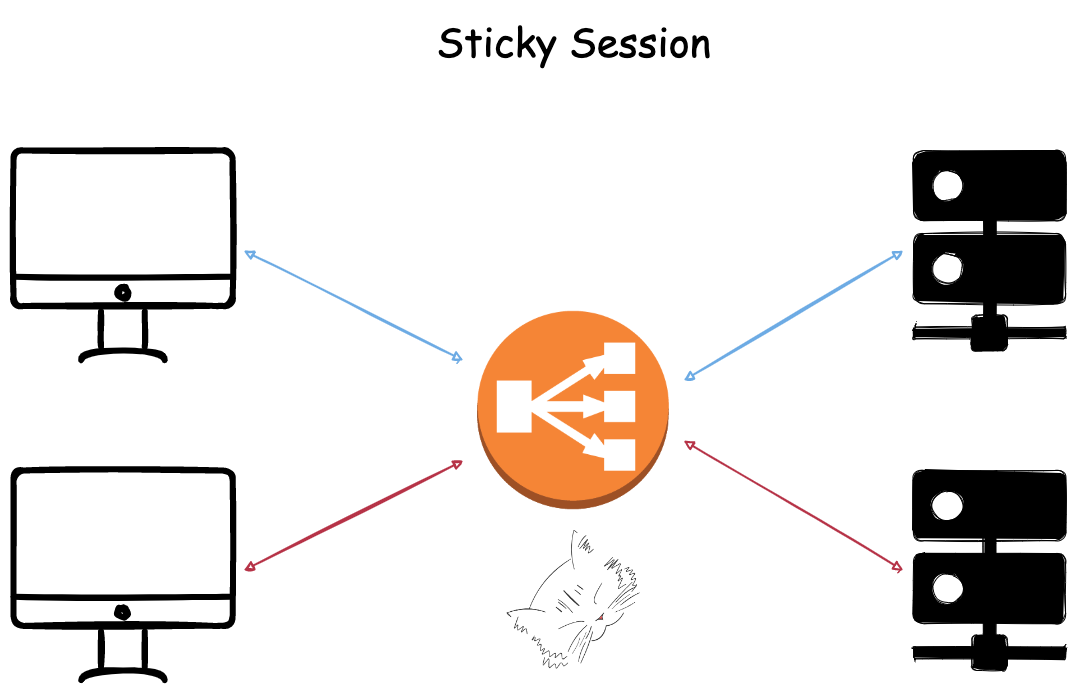
기본적으로 분산되던 클라이언트의 세션 요청이 한 서버에 고정된 것을 확인할 수 있다.
이를 위해 별도의 쿠키를 사용하거나 클라이언트의 IP를 추적하기도 한다.
장단점은 아래와 같다.
- 장점
- 서버 간 세션 공유에 드는 자원을 아낄 수 있다.
- 위와 같은 이유로 세션을 DB가 아닌 메모리에 저장해 빠른 반응속도를 확보할 수 있다.
- 단점
- 특정 서버에만 요청이 몰려 과부하가 올 가능성이 존재한다.
- 서버 하나가 비정상적으로 종료되면 해당 서버에 묶인 세션이 전부 삭제될 위험이 있다.
Session Database
다음으로 생각해 볼 수 있는 방식은 세션만을 저장하는 공통 데이터베이스를 사용하는 것이다.
이는 각자 세션을 공유하는 방식을 근본적으로 해결하는 방식으로, 그림으로 보면 아래와 같다.
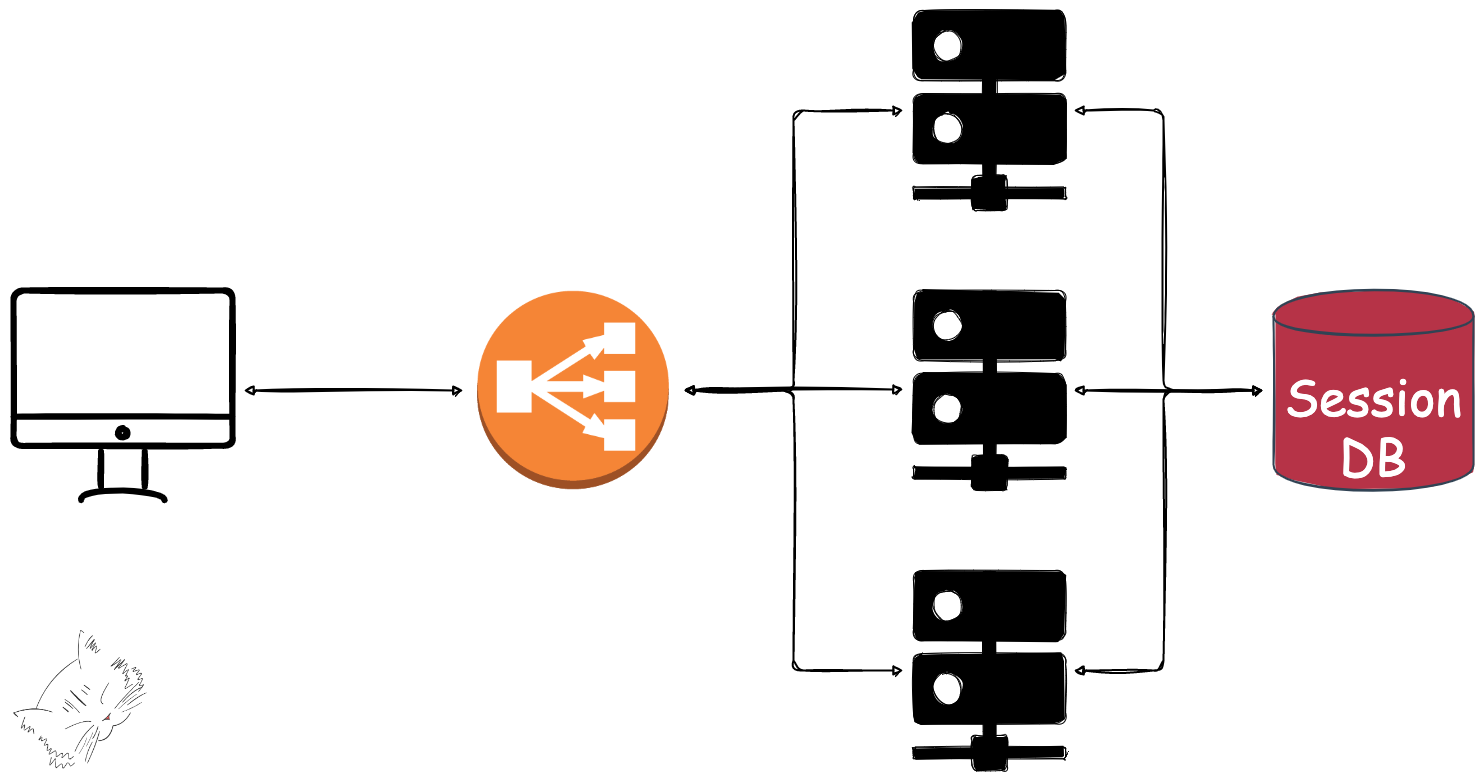
추가로 이와 같은 경우, 디스크를 이용한 세션 저장은 조회 속도가 느리기 때문에
보통 속도가 빠른 인메모리 데이터베이스, 레디스가 많이 사용된다고 한다.
- 장점
- 진정한 의미의 부하 분산과 데이터 정합성 확보
- 단점
- 휘발성 인메모리 데이터베이스를 사용하기 때문에 디스크에 로그 등을 기록해야 한다.
Session Clustering
클러스터링이란 한 마디로 말하면 여러 대의 컴퓨터를 한 대처럼 사용하는 것을 말한다.
세션을 포함한 데이터 정합성 관점에서 봤을 땐 마치 하나의 서버와 데이터베이스를 쓰는 것과 같이 보인다.
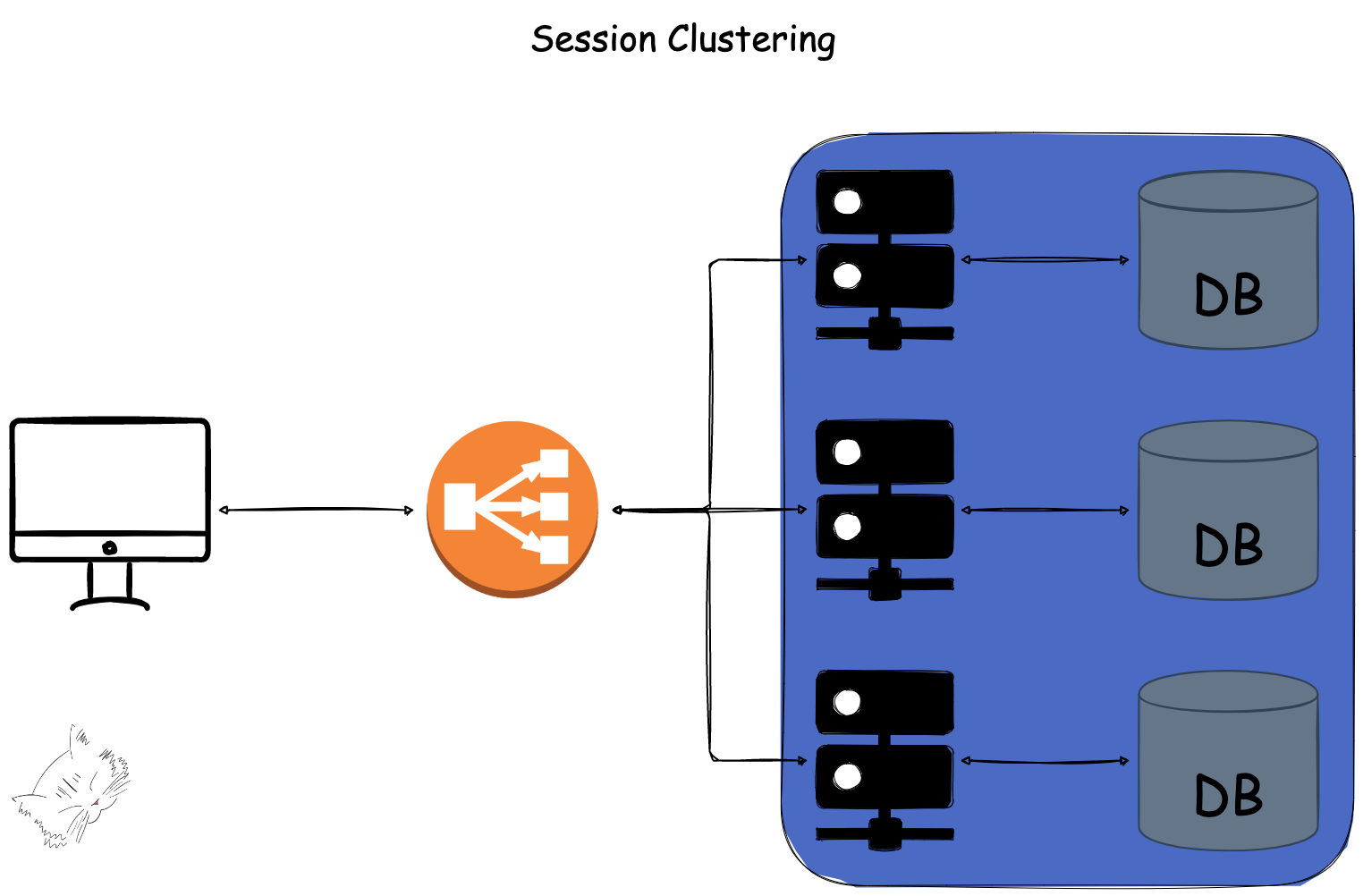
여기에도 크게 두 가지 방식의 전략이 존재하는데, 이는 각각 아래와 같다.
All-To-All
모든 서버가 모든 세션 데이터를 복제해 보유하는 방식이다.
뛰어난 안정성을 자랑하지만 중복 데이터에 의한 메모리 낭비와 서버 수에 비례한 입력, 업데이트 시 트래픽 증가 문제가 있다.
4대 이하의 다중 서버에는 효율이 좋다고 한다.
Primary-Secondary Session Replication
Primay, Secondary 두 대의 서버만 복제 데이터를 가지고 나머지 서버는 세션 아이디만 저장하는 방식이다.
즉, 원래의 세션 서버와 하나의 레플리카 서버에만 세션 데이터가 저장이 된다.
구체적으로는 요청이 들어오면, 해당 요청을 처리한 서버가 Primary Node가 된다.
이어서 남은 서버 중 하나의 서버가 Secondary(Backup) Node가, 나머지 노드는 Proxy Node가 된다.
Proxy Node는 Primary, Secondary Node의 주소와 세션 아이디를 저장하고 있다가
클라이언트로부터 요청이 들어오면 해당 노드로 데이터를 요청하는 역할을 갖게 된다.
안정성이 떨어지는 대신 메모리와 트래픽도 덜 잡아먹는, 위와 정 반대의 장단점을 가진다.
'Development > MSA' 카테고리의 다른 글
| [MSA]분산 트랜잭션(Distributed Transaction) 튜토리얼 (0) | 2023.04.19 |
|---|---|
| [MSA]분산 환경(Distributed Environment)에서의 내부 통신 (2) | 2023.04.16 |
| [MSA]수직적 분할, 수평적 분할, 그리고 (2) | 2023.04.04 |
| [MSA]CAP Theorem (0) | 2023.04.01 |
| [MSA]Microservice Architecture(MSA) 튜토리얼 (0) | 2023.03.17 |
- Total
- Today
- Yesterday
- spring
- Backjoon
- Python
- 백준
- 유럽여행
- 자바
- 맛집
- 알고리즘
- a6000
- 지지
- 여행
- Algorithm
- 스트림
- 유럽
- 면접 준비
- RX100M5
- 동적계획법
- 파이썬
- 중남미
- 세계일주
- 리스트
- 기술면접
- java
- 야경
- 칼이사
- 스프링
- 세계여행
- BOJ
- 남미
- 세모
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |