

티스토리 뷰
[PyTorch]생성적 적대 신경망(GAN - Generative Adversarial Network)
Vagabund.Gni 2024. 12. 9. 17:52목차
지난 글에서는 MNIST데이터셋을 이용한 오토인코더 모델 코드를 분석해 보았다.
[PyTorch]오토인코더(Autoencoder)
목차 지난 글에서는 전이 학습을 구현하고, RNN의 발전에 대해 가볍게 정리했다. [PyTorch]전이 학습(Transfer Learning) [PyTorch]전이 학습(Transfer Learning)목차 전이 학습(Transfer Learning) 전이 학습(Transf
gnidinger.tistory.com
이번 글에서는 Fashion MNIST를 사용한 Vanilla GAN 코드에 대해 살펴본다.
언제 적 GAN이냐고 할지 모르지만, 나는 오늘이 초면이다. 가능한 샅샅이 살펴보겠다.
선 요약
이 글에서 다룰 코드는 다음과 같다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd.variable import Variable
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
import imageio
from tqdm import trange
import numpy as np
from matplotlib import pyplot as plt
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
to_image = transforms.ToPILImage()
trainset = FashionMNIST(root="./data/", train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=100, shuffle=True)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 'T-Shirt','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle Boot'
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.n_features = 128
self.n_out = 784
self.linear = nn.Sequential(
nn.Linear(self.n_features, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.n_out),
nn.Tanh(),
)
def forward(self, x):
x = self.linear(x)
x = x.view(-1, 1, 28, 28)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.n_in = 784
self.n_out = 1
self.linear = nn.Sequential(
nn.Linear(self.n_in, 1024),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, self.n_out),
nn.Sigmoid(),
)
def forward(self, x):
x = x.view(-1, 784)
x = self.linear(x)
return x
generator = Generator().to(device)
discriminator = Discriminator().to(device)
pretrained = False
if pretrained == True:
discriminator.load_state_dict(torch.load("./models/fmnist_disc.pth"))
generator.load_state_dict(torch.load("./models/fmnist_gner.pth"))
g_optim = optim.Adam(generator.parameters(), lr=2e-4)
d_optim = optim.Adam(discriminator.parameters(), lr=2e-4)
g_losses = []
d_losses = []
images = []
criterion = nn.BCELoss()
def noise(n, n_features=128):
return Variable(torch.randn(n, n_features)).to(device)
def label_ones(size):
data = Variable(torch.ones(size, 1))
return data.to(device)
def label_zeros(size):
data = Variable(torch.zeros(size, 1))
return data.to(device)
def train_discriminator(optimizer, real_data, fake_data):
n = real_data.size(0)
optimizer.zero_grad()
prediction_real = discriminator(real_data)
d_loss = criterion(prediction_real, label_ones(n))
prediction_fake = discriminator(fake_data)
g_loss = criterion(prediction_fake, label_zeros(n))
loss = d_loss + g_loss
loss.backward()
optimizer.step()
return loss.item()
def train_generator(optimizer, fake_data):
n = fake_data.size(0)
optimizer.zero_grad()
prediction = discriminator(fake_data)
loss = criterion(prediction, label_ones(n))
loss.backward()
optimizer.step()
return loss.item()
num_epochs = 101
pbar = trange(num_epochs)
test_noise = noise(64)
l = len(trainloader)
for epoch in pbar:
g_loss = 0.0
d_loss = 0.0
for data in trainloader:
imgs, _ = data
n = len(imgs)
fake_data = generator(noise(n)).detach()
real_data = imgs.to(device)
d_loss += train_discriminator(d_optim, real_data, fake_data)
fake_data = generator(noise(n))
g_loss += train_generator(g_optim, fake_data)
img = generator(test_noise).cpu().detach()
img = make_grid(img)
images.append(img)
g_losses.append(g_loss / l)
d_losses.append(d_loss / l)
pbar.set_postfix({"epoch": epoch + 1, "g_loss": g_loss / l, "d_loss": d_loss / l})
torch.save(discriminator.state_dict(), "./models/fmnist_disc.pth")
torch.save(generator.state_dict(), "./models/fmnist_gner.pth")
imgs = [np.array(to_image(i)) for i in images]
imageio.mimsave("./results/fashion_items_vnlgan.gif", imgs)
plt.figure(figsize=(20, 10))
plt.plot(g_losses)
plt.plot(d_losses)
plt.legend(["Generator", "Discriminator"])
plt.title("Loss")
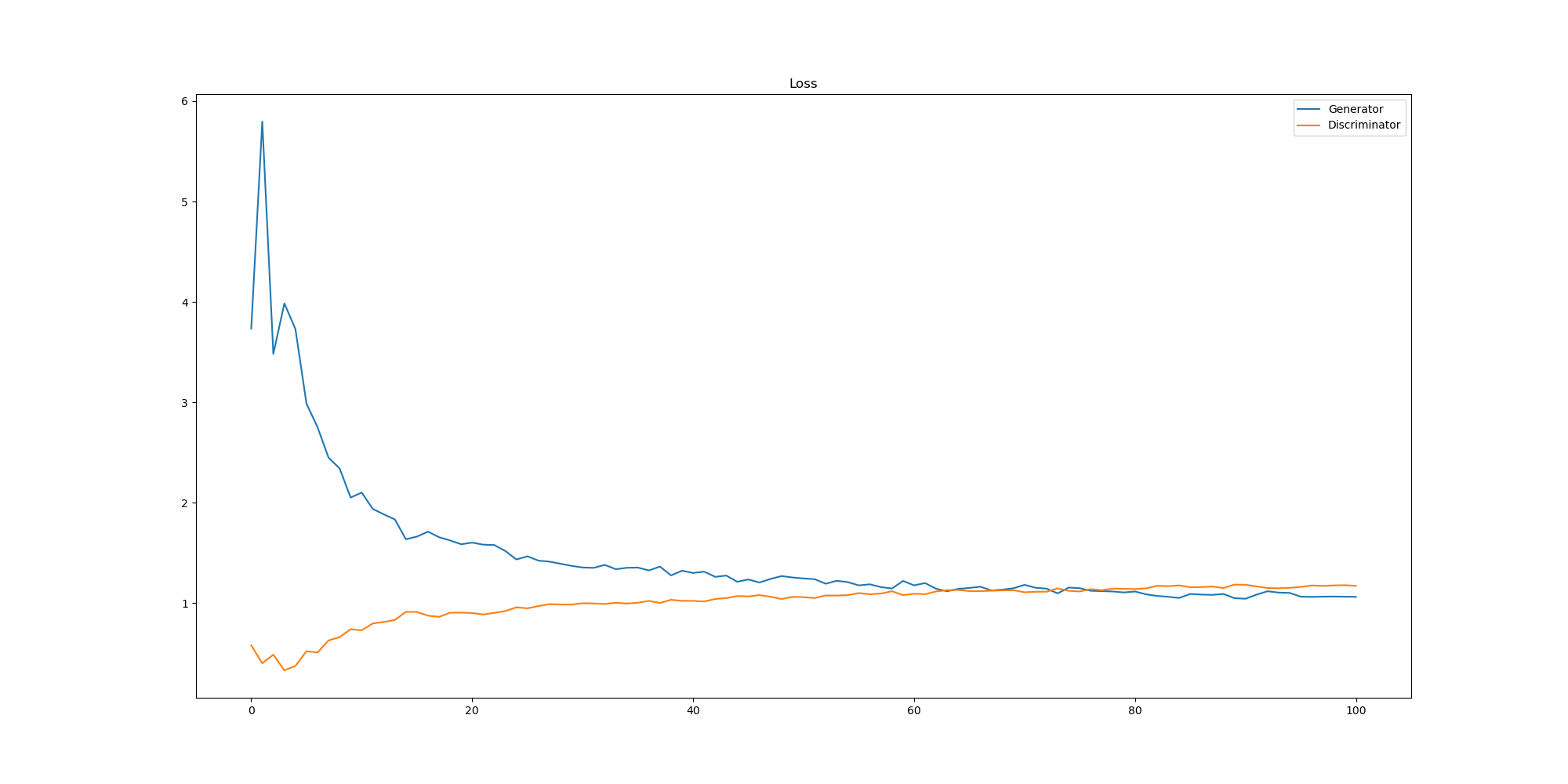
plt.savefig("./results/vnlgan_loss.png")결과는 다음과 같으며,
98%|#########8| 99/101 [13:17<00:15, 7.73s/it, epoch=100, g_loss=1.06, d_loss=1.18]
99%|#########9| 100/101 [13:17<00:07, 7.64s/it, epoch=100, g_loss=1.06, d_loss=1.18]
99%|#########9| 100/101 [13:24<00:07, 7.64s/it, epoch=101, g_loss=1.06, d_loss=1.17]
100%|##########| 101/101 [13:24<00:00, 7.54s/it, epoch=101, g_loss=1.06, d_loss=1.17]
100%|##########| 101/101 [13:24<00:00, 7.97s/it, epoch=101, g_loss=1.06, d_loss=1.17]

핵심 워크플로우는 다음과 같다.
- 데이터 로드 및 전처리
- Fashion MNIST 데이터를 로드하고, [0, 1] 범위의 픽셀 값을 [-1, 1]로 정규화.
- 생성자(Generator) 설계
- 랜덤 노이즈(128차원)를 입력받아 28x28 이미지(784차원 벡터)를 생성.
- 판별자(Discriminator) 설계
- 입력 이미지(784차원 벡터)를 받아 진짜(1) 또는 가짜(0)로 분류.
- 손실 함수 및 최적화
- BCELoss를 사용해 판별자와 생성자의 성능을 측정.
- Adam 최적화 알고리즘으로 네트워크 업데이트.
- 학습 프로세스
- 1단계: 판별자 학습
- 진짜 데이터와 생성된 가짜 데이터를 사용해 판별자의 손실 계산 및 업데이트.
- 2단계: 생성자 학습
- 생성된 가짜 데이터를 사용해 판별자를 속이는 방향으로 생성자의 손실 계산 및 업데이트.
- 1단계: 판별자 학습
- 결과 저장 및 시각화
- 학습된 모델 저장.
- 생성된 이미지로 GIF 생성.
- 학습 손실 그래프 저장.
학습이 오래 걸리는 관계로 101번까지만 에포크를 진행시켰다.
먼저 GAN에 대해 간단하게 알아보고 코드를 뜯어보자.
GAN(Generative Adversarial Network)이란?
GAN(Generative Adversarial Network)은 두 개의 신경망,
생성자(Generator)와 판별자(Discriminator*가 경쟁하며 학습하는 구조로 설계된 딥러닝 모델이다.
생성자는 새로운 데이터를 만들어내는 역할을 하고,
판별자는 진짜 데이터(실제 데이터셋에서 가져온 데이터)와 가짜 데이터(생성자가 만든 데이터)를 구별하는 역할을 한다.
이 구조는 적대적 학습이라고 불리며, 생성자는 판별자를 속이기 위해 더 정교한 데이터를 만들고,
판별자는 속지 않으려고 더 정확히 진짜와 가짜를 구별하도록 학습한다.
결과적으로 두 네트워크는 서로 경쟁하며 동시에 발전하게 된다.
GAN의 중요성은 매우 크다.
특히 이미지 생성, 스타일 변환(예: 흑백 이미지를 컬러로),
이미지 복원(예: 손상된 이미지 복원), 게임 그래픽 생성, 음악 및 텍스트 생성 등 다양한 분야에서 사용된다.
이 코드에서 사용된 GAN
이 코드는 Vanilla GAN이라고 불리는 가장 기본적인 형태의 GAN이다.
Vanilla GAN은 단순히 Fully Connected Layer(완전 연결 계층)만을 사용하며, 복잡한 구조를 가지지 않는다.
코드에 사용된 모델은 Fashion MNIST 데이터셋을 기반으로, 의류 이미지와 유사한 이미지를 생성하도록 학습된다.
라이브러리 불러오기
# PyTorch: 딥러닝 프레임워크로, 신경망 구축, 학습, 최적화 등을 지원한다.
import torch
# PyTorch의 신경망 관련 모듈을 불러온다. 신경망 계층을 정의하는 데 사용된다.
import torch.nn as nn
# PyTorch의 최적화 도구를 불러온다. Adam, SGD 등 다양한 최적화 알고리즘을 제공한다.
import torch.optim as optim
# autograd.variable: 텐서를 감싸서 자동 미분을 지원하는 Variable 클래스를 제공한다.
from torch.autograd.variable import Variable
# torchvision: PyTorch의 컴퓨터 비전 관련 유틸리티 라이브러리로, 데이터셋과 전처리 도구를 포함한다.
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from torchvision.utils import make_grid
# PyTorch 데이터로더 유틸리티를 불러온다. 데이터를 효율적으로 로드하고 배치로 묶는 기능을 제공한다.
from torch.utils.data import DataLoader
# imageio: 이미지 입출력 라이브러리로, GIF와 같은 애니메이션 이미지 생성이 가능하다.
import imageio
# tqdm: 프로그레스 바를 표시하는 라이브러리로, 학습 과정의 진행 상황을 시각적으로 보여준다.
from tqdm import trange
# numpy: 다차원 배열과 수학적 연산을 수행하는 라이브러리로, 데이터 전처리에 유용하다.
import numpy as np
# matplotlib: 데이터 시각화를 위한 라이브러리로, 학습 결과를 그래프로 그리는 데 사용한다.
from matplotlib import pyplot as plt- 1. PyTorch 라이브러리 (torch)
- 딥러닝 연구 및 개발에 사용되는 주요 프레임워크 중 하나이다.
- 신경망 계층 정의, 자동 미분, GPU 가속 등의 기능을 제공한다.
- 2. 신경망 계층 정의 (torch.nn)
- PyTorch에서 신경망 계층(예: Linear, ReLU, Conv2d)을 정의하는 모듈이다.
- 신경망 구조를 구현할 때 사용한다.
- 3. 최적화 알고리즘 (torch.optim)
- 다양한 최적화 알고리즘(예: Adam, SGD)을 제공한다.
- 가중치 업데이트를 효율적으로 수행한다.
- 4. Variable 클래스
- torch.autograd.variable.Variable은 자동 미분을 지원하는 텐서를 감싸는 클래스이다.
- 현재는 PyTorch에서 Variable과 Tensor가 통합되어, 별도로 Variable을 사용할 필요는 없지만, 과거 코드 호환성을 위해 사용되는 경우가 있다.
- 5. torchvision
- PyTorch의 컴퓨터 비전 라이브러리로, 이미지 데이터셋과 전처리(transform) 도구를 제공한다.
- transforms: 이미지 데이터에 대한 전처리(예: 정규화, 텐서 변환)를 수행한다.
- datasets: 사전 정의된 이미지 데이터셋(FashionMNIST, CIFAR10 등)을 불러온다.
- utils: 이미지 텐서를 시각화하기 위한 도구를 포함한다.
- PyTorch의 컴퓨터 비전 라이브러리로, 이미지 데이터셋과 전처리(transform) 도구를 제공한다.
- 6. DataLoader
- 데이터를 배치(batch)로 묶어 효율적으로 처리할 수 있도록 한다.
- 데이터셋에서 샘플링, 배치 구성, 셔플 등의 기능을 수행한다.
- 7. imageio
- 다양한 이미지 형식(GIF, PNG, JPEG 등)을 처리하는 라이브러리이다.
- 이 코드에서는 학습 과정에서 생성된 이미지를 GIF로 저장하는 데 사용된다.
- 8. tqdm
- 반복문 진행 상황을 시각적으로 표시하는 프로그레스 바 라이브러리이다.
- 학습 속도, 남은 시간 등을 실시간으로 확인할 수 있어 유용하다.
- 9. numpy
- 다차원 배열과 수학적 연산을 수행하는 라이브러리이다.
- 딥러닝 모델의 데이터 전처리나 결과 분석에 자주 사용된다.
- 10. matplotlib
- 데이터를 그래프로 시각화하는 라이브러리이다.
- 학습 과정의 손실(loss) 곡선이나 결과 이미지 시각화를 위해 사용된다.
데이터 전처리
# 데이터 전처리 정의
transform = transforms.Compose(
[
# ToTensor(): 이미지를 PyTorch 텐서 형태로 변환.
# 이미지를 [0, 255] 범위에서 [0.0, 1.0] 범위로 스케일링한다.
transforms.ToTensor(),
# Normalize(mean, std): 각 픽셀 값을 정규화.
# mean = 0.5, std = 0.5로 설정하여 데이터를 [-1, 1] 범위로 변환한다.
# (x - mean) / std 계산에 따라, (x - 0.5) / 0.5 = 2x - 1.
transforms.Normalize((0.5,), (0.5,)),
]
)
# ToPILImage: 텐서를 PIL 이미지로 변환하는 유틸리티
to_image = transforms.ToPILImage()
# FashionMNIST 데이터셋 로드
trainset = FashionMNIST(
root="./data/", # 데이터가 저장될 경로
train=True, # 학습용 데이터만 로드
download=True, # 데이터가 없으면 인터넷에서 다운로드
transform=transform, # 위에서 정의한 전처리 적용
)
# DataLoader: 데이터를 배치 단위로 묶어주는 유틸리티
trainloader = DataLoader(
trainset, # 로드할 데이터셋
batch_size=100, # 각 배치에 포함될 데이터 개수
shuffle=True, # 데이터를 무작위로 섞어서 불러오기
)transform의 역
# 데이터 전처리 정의
transform = transforms.Compose(
[
# ToTensor(): 이미지를 PyTorch 텐서 형태로 변환.
# 이미지를 [0, 255] 범위에서 [0.0, 1.0] 범위로 스케일링한다.
transforms.ToTensor(),
# Normalize(mean, std): 각 픽셀 값을 정규화.
# mean = 0.5, std = 0.5로 설정하여 데이터를 [-1, 1] 범위로 변환한다.
# (x - mean) / std 계산에 따라, (x - 0.5) / 0.5 = 2x - 1.
transforms.Normalize((0.5,), (0.5,)),
]
)- transforms.Compose
- 여러 전처리 과정을 순차적으로 적용한다.
- 이 코드에서는 이미지를 텐서로 변환한 후, 정규화를 수행한다.
- transforms.ToTensor()
- PIL 이미지를 PyTorch 텐서로 변환한다.
- 픽셀 값을 [0, 255]에서 [0.0, 1.0] 범위로 스케일링한다.
예를 들어, 값이 128인 픽셀은 128 / 255 = 0.50196으로 변환된다.
- transforms.Normalize((0.5,), (0.5,))
- 텐서의 각 픽셀 값을 정규화한다.
정규화는 다음 공식을 따른다:

따라서 정규화된 값은 2x - 1이 된다.
이 결과, 원래 [0.0, 1.0] 범위의 값이 [-1.0, 1.0]으로 변환된다.
- 텐서의 각 픽셀 값을 정규화한다.
FashionMNIST 데이터셋
# FashionMNIST 데이터셋 로드
trainset = FashionMNIST(
root="./data/", # 데이터가 저장될 경로
train=True, # 학습용 데이터만 로드
download=True, # 데이터가 없으면 인터넷에서 다운로드
transform=transform, # 위에서 정의한 전처리 적용
)- root="./data/": 데이터셋을 저장할 경로를 지정한다.
- train=True: 학습용 데이터셋을 로드한다.
(반대로 테스트 데이터는 train=False로 설정한다.) - download=True: 지정한 경로에 데이터가 없는 경우 자동으로 다운로드한다.
- transform=transform: 로드한 데이터에 전처리를 적용한다.
FashionMNIST 데이터셋?
- 28x28 크기의 흑백 이미지로 구성된다.
- 각 이미지는 10개의 클래스 중 하나에 속한다.
클래스는 T-Shirt, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, Ankle Boot이다.
DataLoader
# DataLoader: 데이터를 배치 단위로 묶어주는 유틸리티
trainloader = DataLoader(
trainset, # 로드할 데이터셋
batch_size=100, # 각 배치에 포함될 데이터 개수
shuffle=True, # 데이터를 무작위로 섞어서 불러오기
)DataLoader의 역할
- 데이터셋을 모델 학습에 적합한 형태로 제공한다.
- 데이터를 배치 크기만큼 묶고, 무작위로 섞는다.
주요 매개변수
- trainset: FashionMNIST 데이터셋 객체.
- batch_size=100: 한 번에 처리할 데이터 개수.
- 예를 들어, 60,000개의 학습 데이터가 있다면 한 에폭에서 총 600번의 배치 처리가 필요하다.
- shuffle=True: 데이터를 무작위로 섞어 과적합 방지.
- 이를 통해 학습이 데이터 순서에 의존하지 않도록 한다.
Generator와 Discriminator 정의
# Generator는 랜덤 노이즈를 입력으로 받아 가짜 이미지를 생성한다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 생성기의 입력 차원: 랜덤 노이즈 벡터 크기
self.n_features = 128
# 출력 차원: 28x28 이미지의 픽셀 수
self.n_out = 784
# Fully Connected Layers와 활성화 함수로 구성된 신경망
self.linear = nn.Sequential(
nn.Linear(self.n_features, 256), # 입력 노이즈를 256차원으로 매핑
nn.LeakyReLU(0.2), # Leaky ReLU 활성화 함수 사용
nn.Linear(256, 512), # 256차원을 512차원으로 매핑
nn.LeakyReLU(0.2),
nn.Linear(512, 1024), # 512차원을 1024차원으로 매핑
nn.LeakyReLU(0.2),
nn.Linear(1024, self.n_out), # 최종적으로 784차원(28x28)으로 매핑
nn.Tanh(), # 출력 값을 -1과 1 사이로 제한
)
def forward(self, x):
# 입력 노이즈를 신경망에 전달
x = self.linear(x)
# 출력 벡터를 28x28 크기의 이미지 형태로 변환
x = x.view(-1, 1, 28, 28)
return x
# Discriminator는 입력 이미지를 받아 진짜인지 가짜인지 판별한다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 판별기의 입력 차원: 28x28 이미지의 픽셀 수
self.n_in = 784
# 출력 차원: 진짜(1) 또는 가짜(0)로 판별하기 위한 1차원 출력
self.n_out = 1
# Fully Connected Layers와 활성화 함수, 드롭아웃으로 구성된 신경망
self.linear = nn.Sequential(
nn.Linear(self.n_in, 1024), # 784차원을 1024차원으로 매핑
nn.LeakyReLU(0.2), # Leaky ReLU 활성화 함수 사용
nn.Dropout(0.3), # 30% 확률로 뉴런 비활성화
nn.Linear(1024, 512), # 1024차원을 512차원으로 매핑
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256), # 512차원을 256차원으로 매핑
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, self.n_out), # 최종적으로 1차원으로 매핑
nn.Sigmoid(), # 출력 값을 0과 1 사이로 제한 (확률로 표현)
)
def forward(self, x):
# 입력 이미지를 1차원 벡터 형태로 변환
x = x.view(-1, 784)
# 신경망에 입력하여 판별 결과 반환
x = self.linear(x)
return xGenerator
# Generator는 랜덤 노이즈를 입력으로 받아 가짜 이미지를 생성한다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 생성기의 입력 차원: 랜덤 노이즈 벡터 크기
self.n_features = 128
# 출력 차원: 28x28 이미지의 픽셀 수
self.n_out = 784
# Fully Connected Layers와 활성화 함수로 구성된 신경망
self.linear = nn.Sequential(
nn.Linear(self.n_features, 256), # 입력 노이즈를 256차원으로 매핑
nn.LeakyReLU(0.2), # Leaky ReLU 활성화 함수 사용
nn.Linear(256, 512), # 256차원을 512차원으로 매핑
nn.LeakyReLU(0.2),
nn.Linear(512, 1024), # 512차원을 1024차원으로 매핑
nn.LeakyReLU(0.2),
nn.Linear(1024, self.n_out), # 최종적으로 784차원(28x28)으로 매핑
nn.Tanh(), # 출력 값을 -1과 1 사이로 제한
)
def forward(self, x):
# 입력 노이즈를 신경망에 전달
x = self.linear(x)
# 출력 벡터를 28x28 크기의 이미지 형태로 변환
x = x.view(-1, 1, 28, 28)
return xGenerator는 랜덤 노이즈를 입력으로 받아 가짜 이미지를 생성하는 역할을 한다.
- 구조:
- 입력으로 고정 크기의 랜덤 벡터(노이즈)를 받는다.
- Fully Connected Layer와 LeakyReLU 활성화 함수로 구성되어 있다.
- 최종적으로 Tanh 활성화 함수를 사용하여 출력 값을 -1과 1 사이로 제한한다.
이는 데이터셋의 정규화된 범위와 일치시키기 위해서이다.
- Forward Pass:
- 입력 노이즈는 일련의 선형 변환을 거치며 점차 복잡한 패턴을 학습한다.
- 마지막 출력은 28x28 크기의 이미지를 생성하도록 변환된다.
- 주요 요소:
- nn.Linear: Fully Connected Layer로 입력 데이터를 새로운 차원으로 변환.
- LeakyReLU(0.2): 음수 입력에 대해 0.2의 기울기를 적용하여 죽은 뉴런 문제를 완화.
- Tanh: 출력 값을 [-1, 1]로 정규화.
Discriminator
# Discriminator는 입력 이미지를 받아 진짜인지 가짜인지 판별한다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 판별기의 입력 차원: 28x28 이미지의 픽셀 수
self.n_in = 784
# 출력 차원: 진짜(1) 또는 가짜(0)로 판별하기 위한 1차원 출력
self.n_out = 1
# Fully Connected Layers와 활성화 함수, 드롭아웃으로 구성된 신경망
self.linear = nn.Sequential(
nn.Linear(self.n_in, 1024), # 784차원을 1024차원으로 매핑
nn.LeakyReLU(0.2), # Leaky ReLU 활성화 함수 사용
nn.Dropout(0.3), # 30% 확률로 뉴런 비활성화
nn.Linear(1024, 512), # 1024차원을 512차원으로 매핑
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256), # 512차원을 256차원으로 매핑
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, self.n_out), # 최종적으로 1차원으로 매핑
nn.Sigmoid(), # 출력 값을 0과 1 사이로 제한 (확률로 표현)
)
def forward(self, x):
# 입력 이미지를 1차원 벡터 형태로 변환
x = x.view(-1, 784)
# 신경망에 입력하여 판별 결과 반환
x = self.linear(x)
return xDiscriminator는 입력 데이터를 진짜(1)인지 가짜(0)인지 판별하는 역할을 한다.
- 구조:
- 입력으로 28x28 크기의 이미지를 받는다.
- Fully Connected Layer와 LeakyReLU 활성화 함수, Dropout으로 구성되어 있다.
- 마지막에 Sigmoid 활성화 함수로 결과를 0과 1 사이의 확률로 반환한다.
- Forward Pass:
- 입력 이미지는 Flatten(784차원 벡터)으로 변환된다.
- 신경망은 진짜와 가짜를 구별하는 패턴을 학습한다.
- 주요 요소:
- nn.Dropout(0.3): 학습 중 일부 뉴런을 랜덤 하게 비활성화하여 과적합 방지.
- LeakyReLU(0.2): Generator와 동일하게 음수 입력에 작은 기울기를 부여.
- Sigmoid: 출력 값을 확률로 변환(0~1).
Generator와 Discriminator의 상호작용
- Generator는 Discriminator를 속이기 위해 진짜 같은 이미지를 생성하려고 학습한다.
- Discriminator는 Generator가 생성한 이미지를 가짜로 판별하려고 학습한다.
- 이 두 네트워크는 경쟁하며 발전하여 Generator는 더욱 현실감 있는 이미지를 생성할 수 있게 된다.
노이즈 생성 및 라벨링 함수
# 랜덤 노이즈를 생성하는 함수
def noise(n, n_features=128):
"""
n: 생성할 노이즈 샘플의 개수.
n_features: 노이즈 벡터의 차원. 기본값은 128이다.
반환값: [n, n_features] 크기의 랜덤 노이즈 텐서를 반환.
"""
# torch.randn(n, n_features): 평균이 0, 표준편차가 1인 정규분포에서 난수를 생성.
# Variable: PyTorch의 텐서를 래핑하여 자동 미분에 사용할 수 있도록 한다.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
return Variable(torch.randn(n, n_features)).to(device)
# Discriminator가 '진짜' 데이터를 판별하도록 학습시키기 위해 필요한 라벨(1)을 생성.
def label_ones(size):
"""
size: 생성할 라벨의 개수.
반환값: [size, 1] 크기의 값이 모두 1인 텐서를 반환.
"""
# torch.ones(size, 1): 값이 모두 1인 텐서를 생성.
# Variable: 자동 미분을 위한 래핑.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
data = Variable(torch.ones(size, 1))
return data.to(device)
# Discriminator가 '가짜' 데이터를 판별하도록 학습시키기 위해 필요한 라벨(0)을 생성.
def label_zeros(size):
"""
size: 생성할 라벨의 개수.
반환값: [size, 1] 크기의 값이 모두 0인 텐서를 반환.
"""
# torch.zeros(size, 1): 값이 모두 0인 텐서를 생성.
# Variable: 자동 미분을 위한 래핑.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
data = Variable(torch.zeros(size, 1))
return data.to(device)노이즈 생성 함수
# 랜덤 노이즈를 생성하는 함수
def noise(n, n_features=128):
"""
n: 생성할 노이즈 샘플의 개수.
n_features: 노이즈 벡터의 차원. 기본값은 128이다.
반환값: [n, n_features] 크기의 랜덤 노이즈 텐서를 반환.
"""
# torch.randn(n, n_features): 평균이 0, 표준편차가 1인 정규분포에서 난수를 생성.
# Variable: PyTorch의 텐서를 래핑하여 자동 미분에 사용할 수 있도록 한다.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
return Variable(torch.randn(n, n_features)).to(device)- 이 함수는 Generator의 입력으로 사용할 랜덤 노이즈를 생성한다.
- 랜덤 노이즈의 역할:
- GAN에서 Generator는 입력 데이터가 없어도 학습이 가능해야 한다.
- 따라서 랜덤 한 입력 벡터(노이즈)를 사용하여 다양한 데이터 분포를 학습하게 만든다.
- 매개변수:
- n: 생성할 샘플의 개수.
- n_features: 노이즈 벡터의 차원. 기본값은 128이며, Generator의 입력 크기와 동일하다.
- 과정:
- torch.randn(n, n_features)는 정규분포에서 난수를 생성하여 [n, n_features] 크기의 텐서를 만든다.
- 생성된 텐서를 Variable로 감싸서 PyTorch의 자동 미분 기능을 사용할 수 있게 한다.
- .to(device)로 텐서를 GPU 또는 CPU로 이동한다.
- 결과: [n, n_features] 크기의 랜덤 노이즈 텐서를 반환한다.
라벨 생성 함수
label_ones 함수
# Discriminator가 '진짜' 데이터를 판별하도록 학습시키기 위해 필요한 라벨(1)을 생성.
def label_ones(size):
"""
size: 생성할 라벨의 개수.
반환값: [size, 1] 크기의 값이 모두 1인 텐서를 반환.
"""
# torch.ones(size, 1): 값이 모두 1인 텐서를 생성.
# Variable: 자동 미분을 위한 래핑.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
data = Variable(torch.ones(size, 1))
return data.to(device)- 역할: Discriminator가 진짜 데이터를 처리할 때 사용할 라벨(값이 1)을 생성한다.
- 매개변수:
- size: 생성할 라벨의 개수. 예를 들어, 배치 크기만큼의 라벨이 필요하다.
- 과정:
- torch.ones(size, 1)로 [size, 1] 크기의 값이 모두 1인 텐서를 생성.
- Variable로 감싸서 자동 미분에 사용 가능하게 만든다.
- .to(device)로 GPU나 CPU에 맞게 텐서를 이동한다.
- 결과: [size, 1] 크기의 값이 모두 1인 텐서를 반환.
label_zeros 함수
# Discriminator가 '가짜' 데이터를 판별하도록 학습시키기 위해 필요한 라벨(0)을 생성.
def label_zeros(size):
"""
size: 생성할 라벨의 개수.
반환값: [size, 1] 크기의 값이 모두 0인 텐서를 반환.
"""
# torch.zeros(size, 1): 값이 모두 0인 텐서를 생성.
# Variable: 자동 미분을 위한 래핑.
# .to(device): 텐서를 GPU나 CPU에 맞게 이동.
data = Variable(torch.zeros(size, 1))
return data.to(device)- 역할: Discriminator가 가짜 데이터를 처리할 때 사용할 라벨(값이 0)을 생성한다.
- 매개변수와 동작은 label_ones와 동일하며, 값이 모두 0인 텐서를 반환한다.
왜 중요한가?
- 노이즈 생성:
- Generator는 랜덤 노이즈를 입력으로 받아 진짜 같은 데이터를 생성하는 데 초점을 맞춘다.
- 이 랜덤 노이즈는 학습 중 Generator의 다양성을 높이고 데이터 분포를 효과적으로 학습하게 돕는다.
- 라벨 생성:
- Discriminator가 진짜와 가짜 데이터를 구분하는 학습을 할 수 있게 라벨을 제공한다.
- 학습 손실 계산 시 필요하며, Discriminator가 더 정확히 판별하도록 돕는다.
손실 함수와 옵티마이저
# 손실 함수 정의
# nn.BCELoss()는 Binary Cross Entropy Loss로, 이진 분류 문제에 적합한 손실 함수이다.
# Discriminator는 실제 데이터를 "1", 가짜 데이터를 "0"으로 예측하도록 학습된다.
# 이를 위해 예측값(prediction)과 실제 라벨(label) 간의 차이를 계산하여 손실을 구한다.
criterion = nn.BCELoss()
# Generator와 Discriminator를 각각 학습하기 위한 Adam 옵티마이저 정의
# Generator와 Discriminator의 매개변수(parameter)를 각각 최적화한다.
# Adam 옵티마이저는 학습 속도를 빠르게 하면서 안정적인 학습을 지원하는 알고리즘이다.
# 학습률(learning rate)은 0.0002로 설정한다.
g_optim = optim.Adam(generator.parameters(), lr=2e-4) # Generator의 매개변수 최적화
d_optim = optim.Adam(discriminator.parameters(), lr=2e-4) # Discriminator의 매개변수 최적화손실 함수: Binary Cross Entropy Loss (BCELoss)
BCELoss는 이진 분류 문제에서 사용하는 손실 함수로, 다음과 같은 목적을 가진다:
- Discriminator가 진짜 데이터를 1로, 가짜 데이터를 0으로 정확히 예측하도록 학습.
- Generator가 가짜 데이터를 생성해 Discriminator가 이를 1로 예측하도록 속이는 방향으로 학습.
BCELoss 공식
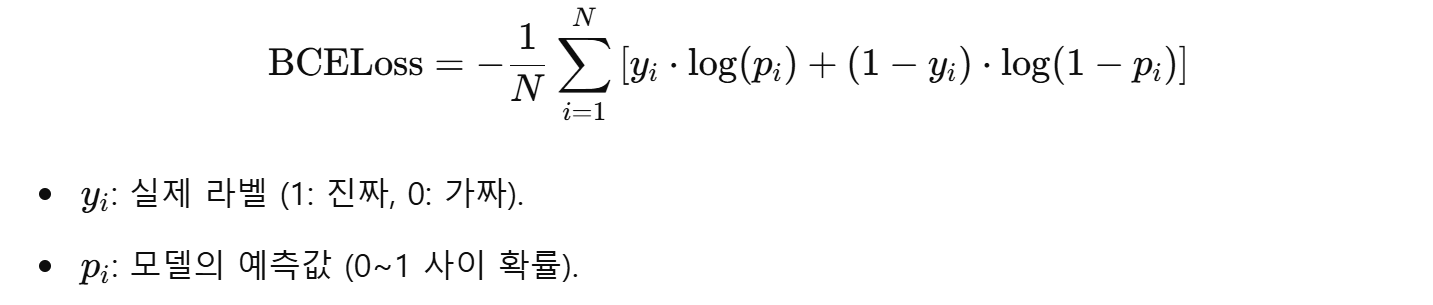
왜 BCELoss를 사용하나?
- GAN에서는 출력이 이진 확률값 (진짜 또는 가짜)으로 나타나므로, 이진 분류에 특화된 BCELoss가 적합하다.
- 출력값에 Sigmoid 활성화 함수를 사용하여 확률로 변환한 후, 손실을 계산한다.
옵티마이저: Adam
Adam 옵티마이저는 학습 속도를 빠르게 하고, 그 과정에서 진동(oscillation)을 줄이며 안정적인 학습을 제공하는 알고리즘이다.
Adam의 특징
- 모멘텀 (Momentum):
- 이전의 기울기 정보를 반영하여 학습을 가속화한다.
- 적응적 학습률 (Adaptive Learning Rate):
- 각 매개변수마다 학습률을 독립적으로 조정하여 학습 안정성을 높인다.
Adam 공식

왜 Adam을 선택했나?
- GAN에서는 Generator와 Discriminator 간의 상호작용이 민감하므로, 학습률을 효과적으로 조절하는 Adam이 적합하다.
- 빠른 수렴 속도와 안정성을 제공하여 두 네트워크 간의 균형을 유지한다.
훈련 함수
def train_discriminator(optimizer, real_data, fake_data):
# 옵티마이저 초기화 (기존의 그라디언트 제거)
optimizer.zero_grad()
# 진짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction_real = discriminator(real_data)
# 진짜 데이터를 1로 라벨링한 손실 계산
d_loss = criterion(prediction_real, label_ones(real_data.size(0)))
# 가짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction_fake = discriminator(fake_data)
# 가짜 데이터를 0으로 라벨링한 손실 계산
g_loss = criterion(prediction_fake, label_zeros(fake_data.size(0)))
# 판별자의 총 손실은 진짜 데이터와 가짜 데이터의 손실 합
loss = d_loss + g_loss
# 역전파로 그라디언트 계산
loss.backward()
# 판별자 파라미터 업데이트
optimizer.step()
# 손실 값을 반환
return loss.item()
def train_generator(optimizer, fake_data):
# 옵티마이저 초기화 (기존의 그라디언트 제거)
optimizer.zero_grad()
# 가짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction = discriminator(fake_data)
# 판별자를 속이기 위해 가짜 데이터를 1로 라벨링한 손실 계산
loss = criterion(prediction, label_ones(fake_data.size(0)))
# 역전파로 그라디언트 계산
loss.backward()
# 생성자 파라미터 업데이트
optimizer.step()
# 손실 값을 반환
return loss.item()train_discriminator
def train_discriminator(optimizer, real_data, fake_data):
# 옵티마이저 초기화 (기존의 그라디언트 제거)
optimizer.zero_grad()
# 진짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction_real = discriminator(real_data)
# 진짜 데이터를 1로 라벨링한 손실 계산
d_loss = criterion(prediction_real, label_ones(real_data.size(0)))
# 가짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction_fake = discriminator(fake_data)
# 가짜 데이터를 0으로 라벨링한 손실 계산
g_loss = criterion(prediction_fake, label_zeros(fake_data.size(0)))
# 판별자의 총 손실은 진짜 데이터와 가짜 데이터의 손실 합
loss = d_loss + g_loss
# 역전파로 그라디언트 계산
loss.backward()
# 판별자 파라미터 업데이트
optimizer.step()
# 손실 값을 반환
return loss.item()Discriminator는 진짜 데이터를 1(참)로, 가짜 데이터를 0(거짓)으로 분류하도록 학습한다.
초기화 단계
optimizer.zero_grad()를 통해 이전 학습에서 계산된 그라디언트를 초기화한다.
이는 새로 계산된 그라디언트가 기존 값에 영향을 받지 않도록 한다.
진짜 데이터에 대한 손실 계산
prediction_real = discriminator(real_data)
d_loss = criterion(prediction_real, label_ones(real_data.size(0)))- real_data는 실제 데이터셋에서 가져온 배치.
- 판별자가 진짜 데이터를 1로 예측하도록 Binary Cross Entropy Loss(BCELoss)를 계산한다.
가짜 데이터에 대한 손실 계산
prediction_fake = discriminator(fake_data)
g_loss = criterion(prediction_fake, label_zeros(fake_data.size(0)))- fake_data는 Generator가 생성한 가짜 데이터.
- 판별자가 가짜 데이터를 0으로 예측하도록 손실을 계산한다.
총 손실 계산 및 업데이트
loss = d_loss + g_loss
loss.backward()
optimizer.step()- 진짜 데이터와 가짜 데이터에서 계산된 손실을 합산하여 총손실로 정의한다.
- 역전파(Backpropagation)를 통해 그라디언트를 계산하고, 판별자의 파라미터를 업데이트한다.
train_generator
def train_generator(optimizer, fake_data):
# 옵티마이저 초기화 (기존의 그라디언트 제거)
optimizer.zero_grad()
# 가짜 데이터를 입력으로 받아 판별자의 예측값 계산
prediction = discriminator(fake_data)
# 판별자를 속이기 위해 가짜 데이터를 1로 라벨링한 손실 계산
loss = criterion(prediction, label_ones(fake_data.size(0)))
# 역전파로 그라디언트 계산
loss.backward()
# 생성자 파라미터 업데이트
optimizer.step()
# 손실 값을 반환
return loss.item()Generator는 가짜 데이터를 판별자가 1(참)로 예측하도록 학습한다.
즉, 판별자를 속이는 방향으로 학습이 진행된다.
초기화 단계
optimizer.zero_grad()를 통해 기존의 그라디언트를 초기화한다.
판별자를 속이기 위한 손실 계산
prediction = discriminator(fake_data)
loss = criterion(prediction, label_ones(fake_data.size(0)))- fake_data는 Generator가 생성한 가짜 데이터.
- 판별자가 이 데이터를 1로 예측하도록 손실을 계산한다.
손실 계산 및 업데이트
loss.backward()
optimizer.step()- 역전파를 통해 그라디언트를 계산하고, 생성자의 파라미터를 업데이트한다.
요약
- train_discriminator: 판별자가 진짜와 가짜 데이터를 올바르게 구분하도록 학습한다.
- train_generator: 생성자가 판별자를 속여 가짜 데이터를 진짜처럼 보이게 학습한다.
- 두 함수는 서로 경쟁하며 학습하여 생성된 데이터의 품질이 점점 개선된다.
학습 루프
# 학습 루프
for epoch in trange(num_epochs): # 지정된 에폭 수(num_epochs)만큼 반복
g_loss = 0.0 # Generator 손실 초기화
d_loss = 0.0 # Discriminator 손실 초기화
for data in trainloader: # DataLoader에서 배치를 하나씩 불러옴
imgs, _ = data # imgs는 실제 데이터(이미지), _는 해당 라벨 (사용하지 않음)
real_data = imgs.to(device) # 실제 데이터를 GPU 또는 CPU로 이동
# Generator로 가짜 데이터 생성
fake_data = generator(noise(len(imgs))).detach()
# fake_data는 Generator가 생성한 가짜 데이터
# detach()를 사용하여 Generator의 가중치 업데이트가 이루어지지 않도록 함
# Discriminator 학습: 진짜(real_data)와 가짜(fake_data)를 판별
d_loss += train_discriminator(d_optim, real_data, fake_data)
# Generator로 새로운 가짜 데이터 생성
fake_data = generator(noise(len(imgs)))
# Generator 학습: 생성한 fake_data를 진짜처럼 속이도록 학습
g_loss += train_generator(g_optim, fake_data)
# 학습 중간 결과를 저장
img = generator(test_noise).cpu().detach() # 고정된 노이즈로 이미지 생성
img = make_grid(img) # 여러 이미지를 하나로 묶어 그리드 형태로 만듦
images.append(img) # 생성된 이미지를 리스트에 추가에포크 반복
for epoch in trange(num_epochs):- 전체 데이터셋을 학습에 사용하는 반복 횟수를 지정.
- trange는 진행 상황을 시각적으로 보여준다.
손실 초기화
g_loss = 0.0
d_loss = 0.0- Generator와 Discriminator의 손실 값을 각 에폭마다 누적하기 위해 초기화한다.
데이터 배치 처리
for data in trainloader:
imgs, _ = data
real_data = imgs.to(device)- trainloader에서 데이터를 배치 크기만큼 불러온다.
- imgs는 실제 이미지 데이터(4차원 텐서 형태)이며, 라벨 데이터 _은 사용하지 않는다.
- FashionMNIST의 라벨은 0부터 9까지의 정수로, 각 클래스(의류 종류)에 해당한다
- 이미지를 device로 전송하여 GPU(또는 CPU)에서 처리하도록 한다.
가짜 데이터 생성
fake_data = generator(noise(len(imgs))).detach()- Generator를 통해 랜덤 노이즈로부터 가짜 데이터를 생성한다.
- detach()를 사용하여 역전파가 Generator로 전달되지 않도록 한다. 이는 Discriminator 학습 단계에서 Generator의 가중치를 고정하기 위함이다.
Discriminator 학습
d_loss += train_discriminator(d_optim, real_data, fake_data)- train_discriminator 함수를 호출하여 Discriminator를 학습한다.
- 진짜 데이터(real_data)는 "진짜"로, 가짜 데이터(fake_data)는 "가짜"로 판별하도록 학습.
Generator 학습
fake_data = generator(noise(len(imgs)))
g_loss += train_generator(g_optim, fake_data)- 새로운 노이즈를 입력하여 가짜 데이터를 생성한다.
- train_generator 함수를 호출하여 Generator를 학습한다.
- Generator는 가짜 데이터를 진짜처럼 속이도록 학습하며, Discriminator의 판별 결과에 따라 손실이 계산된다.
중간 결과 저장
img = generator(test_noise).cpu().detach()
img = make_grid(img)
images.append(img)- 고정된 test_noise로 Generator의 성능을 확인한다.
- 생성된 이미지를 make_grid로 하나의 그리드 이미지로 묶고 리스트에 저장한다.
중요한 개념
- detach():
- Generator가 생성한 가짜 데이터는 Discriminator 학습에 사용된다.
- 이때, detach()를 사용하여 가짜 데이터를 생성한 Generator의 그래프와 분리한다.
- Generator의 가중치가 업데이트되지 않도록 보장한다.
- Discriminator와 Generator의 번갈아 학습:
- GAN의 핵심은 두 네트워크가 서로 경쟁하면서 성능을 개선하는 것이다.
- Discriminator는 진짜와 가짜를 정확히 구분하도록 학습하고, Generator는 Discriminator를 속이도록 학습한다.
이 루프는 두 네트워크 간의 경쟁을 통해 점진적으로 가짜 데이터의 품질을 개선한다.
결과 저장
# 학습 중 생성된 이미지를 GIF로 저장하고, 손실 그래프를 저장하는 코드
# 'images' 리스트에 저장된 학습 중 생성된 이미지를 순회하며, 각 이미지를 NumPy 배열로 변환한다.
# 'to_image'는 PyTorch 텐서를 PIL 이미지로 변환하는 함수다.
imgs = [np.array(to_image(i)) for i in images]
# 'imageio.mimsave'를 사용하여 여러 이미지를 하나의 GIF 파일로 저장한다.
# 'fashion_items_vnlgan.gif'는 저장될 파일의 이름이다.
# 'imgs'는 GIF로 저장할 이미지 프레임들의 리스트다.
imageio.mimsave("./results/fashion_items_vnlgan.gif", imgs)
# 학습 동안의 Generator와 Discriminator의 손실 변화를 시각화하기 위해 그래프를 그린다.
plt.figure(figsize=(20, 10)) # 그래프의 크기를 설정한다.
plt.plot(g_losses) # Generator의 손실 값 리스트를 그래프에 추가한다.
plt.plot(d_losses) # Discriminator의 손실 값 리스트를 그래프에 추가한다.
plt.legend(["Generator", "Discriminator"]) # 그래프의 범례를 추가한다.
plt.title("Loss") # 그래프 제목을 설정한다.
plt.savefig("./results/vnlgan_loss.png") # 그래프를 PNG 이미지로 저장한다.이미지 저장 과정
imgs = [np.array(to_image(i)) for i in images]- images 리스트는 학습 과정에서 생성된 이미지들의 PyTorch 텐서를 포함한다.
- to_image(i)는 PyTorch 텐서 i를 PIL 이미지로 변환한다.
이 작업은 GIF 저장을 위해 PIL 이미지를 NumPy 배열로 변환해야 하기 때문이다. - np.array(to_image(i))는 PIL 이미지를 NumPy 배열로 변환한다. NumPy 배열은 GIF 생성 라이브러리에서 사용 가능하다.
GIF 저장
imageio.mimsave("./results/fashion_items_vnlgan.gif", imgs)- imageio.mimsave는 여러 프레임 이미지를 하나의 GIF 파일로 합친다.
- ./results/fashion_items_vnlgan.gif는 결과 GIF 파일이 저장될 경로와 파일명이다.
- imgs는 GIF 파일에 포함될 이미지들의 리스트다.
손실 그래프 시각화
plt.figure(figsize=(20, 10))
plt.plot(g_losses)
plt.plot(d_losses)
plt.legend(["Generator", "Discriminator"])
plt.title("Loss")
plt.savefig("./results/vnlgan_loss.png")- plt.figure(figsize=(20, 10)): 그래프의 크기를 지정한다. 가로 20인치, 세로 10인치 크기로 설정.
- plt.plot(g_losses): Generator의 손실 값을 그래프로 그린다.
- plt.plot(d_losses): Discriminator의 손실 값을 그래프로 그린다.
- plt.legend(["Generator", "Discriminator"]): 그래프의 각 선이 무엇을 의미하는지 범례를 추가한다.
- plt.title("Loss"): 그래프의 제목을 "Loss"로 설정한다.
- plt.savefig("./results/vnlgan_loss.png"): 그래프를 PNG 이미지 파일로 저장한다.
결론
이렇게 해서 Fashion MNIST를 사용한 Vanilla GAN 코드에 대해 처음으로 알아보았다.
서로 경쟁하도록 학습시키면서 효율을 뽑아낸다는 발상이 재미있었고,
의외로 구현 자체는 그다지 어렵지 않다는 것도 재미있었다.
실전까지는 아직 먼 것 같지만, 그래도 뭔가 기술이 최근으로 진입한 느낌이 들어 기분이 좋다.
계속 가보자고.
끝!
'Python > PyTorch' 카테고리의 다른 글
| [PyTorch]설명 가능한 AI - CAM (1) | 2024.12.16 |
|---|---|
| [PyTorch]비지도 학습 - 깊은 K-평균 알고리즘 (오토인코더 + K-평균 알고리즘) (0) | 2024.12.10 |
| [PyTorch]오토인코더(Autoencoder) (2) | 2024.12.04 |
| [Pytorch]Vanilla RNN과 확장된 기법들: LSTM, GRU, Bidirectional LSTM, Transformer (2) | 2024.12.03 |
| [PyTorch]전이 학습(Transfer Learning) (0) | 2024.11.27 |
| [PyTorch]Vanilla RNN을 활용한 코스피 예측 문제 (1) | 2024.11.26 |
- Total
- Today
- Yesterday
- 남미
- 스트림
- 중남미
- 여행
- 리스트
- a6000
- Algorithm
- 면접 준비
- 파이썬
- 야경
- 맛집
- 기술면접
- 유럽여행
- 칼이사
- 알고리즘
- RX100M5
- 지지
- 스프링
- java
- 세계여행
- 세모
- Backjoon
- Python
- 동적계획법
- 세계일주
- 유럽
- 자바
- 백준
- BOJ
- spring
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |