

티스토리 뷰
크롤링(Crawling), 혹은 스크래핑(Scraping)은 웹 페이지를 그대로 가져와서
거기서 데이터를 추출해 내는 행위를 가리키는 단어이다.
https://namu.wiki/w/%ED%81%AC%EB%A1%A4%EB%A7%81
크롤링 - 나무위키
이 저작물은 CC BY-NC-SA 2.0 KR에 따라 이용할 수 있습니다. (단, 라이선스가 명시된 일부 문서 및 삽화 제외) 기여하신 문서의 저작권은 각 기여자에게 있으며, 각 기여자는 기여하신 부분의 저작권
namu.wiki
공공데이터와 같은 데이터를 제외하고 별개의 데이터를 수집하려면 반드시 필요한 기술인데,
특히 대량의 데이터를 모아 가공하고 머신러닝을 시키기 위한 데이터 파이프라인에 필수적이라고 할 수 있다.
이 글에서는 Python과 Selenium, 그리고 크롬 웹 드라이버를 이용해 간단한 크롤링 로직을 작성하는 법에 대해 다룬다.
물론 늘 그렇듯 급하게 필요한 경우라면 아래의 코드를 보고 복붙만 해도 사용할 수 있게 만들었다.
그럼 복붙으로 끝내는 셀레늄 크롤링, 시작해 보자.
Selenium
먼저 우리가 사용하게 될 기술에 대해 간단히 짚고 넘어가자.
셀레늄은 웹 앱 자동화 및 테스트를 위한 소프트웨어이다.
셀레늄 (소프트웨어) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 셀레늄(Selenium)은 웹 애플리케이션 자동화 및 테스트를 위한 포터블 프레임워크이다. 셀레늄은 테스트 스크립트 언어를 학습할 필요 없이 기능 테스트를 만들
ko.wikipedia.org
당연히 기능 테스트를 위한 수많은 기능을 제공하지만,
여기서는 크롬 웹 드라이버를 이용해 원하는 정보를 크롤링해오는 도구로 사용하겠다.
여기서 크롬 웹 드라이버를 제어한다는 뜻은
마치 사람이 브라우저를 다루는 것처럼 여러 가지 행동을 시킬 수 있다는 말이다.
webdriver_config.py
시작하기 전에 먼저, 별도의 파일에 크롬 웹 드라이버를 위한 설정을 구현해 놓자.
이렇게 하는 이유는 당연히 코드 중복을 줄이고 필요할 때마다 불러서 사용하기 위함이다.
참고로 이 글에서 다루게 될 셀레늄 크롤링의 패키지는 아래와 같이 단순하게 생겼다.

우선 필요한 라이브러리를 설치하자. 총 두 개의 라이브러리가 필요하다.
pip install selenium webdriver_manager여기서 두 번째로 설치하는 webdriver_manager는 셀레늄에서 웹 드라이버의 버전 관리를 자동화해 주는 도구이다.
이를 사용하면 웹 드라이버의 최신 버전을 자동으로 다운로드하고 관리할 수 있다.
따라서 수동으로 웹 드라이버를 다운로드하고 경로를 설정하는 번거로움을 피할 수 있도록 도와준다고 할 수 있다.
설치가 끝났으면 webdriver_config.py 파일을 만들고 아래와 같이 구현한다.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
def setup_chrome_driver():
chrome_options = Options()
# chrome_options.add_argument("headless") # 브라우저 실행 안 함
# chrome_options.add_argument("--disable-gpu") # GPU 사용 안 함
# chrome_options.add_argument('--disable-gpu') # Linux에서 headless 사용시 필요함
chrome_options.add_argument("--start-fullscreen") # 최대 크기로 시작
chrome_options.add_argument("--disable-extensions") # 확장 프로그램 사용 안 함
chrome_options.add_argument("--disable-popup-blocking") # 팝업 비활성화
chrome_options.add_argument("--disable-dev-shm-usage") # CI가 구현되었거나 Docker를 사용하는 경우
chrome_options.add_argument("--ignore-certificate-errors") # '안전하지 않은 페이지' 스킵
chrome_options.add_argument("--remote-allow-origins=*") # 웹 드라이버가 어떤 원격 주소에서든지 접근 허용
chrome_options.add_argument("lang=en_US")
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()), options=chrome_options
)
return driver별 특별할 건 없고, 셀레늄을 사용하여 크롬 웹 드라이버를 설정하고 초기화하는 함수를 정의했다.
나머지 필요한 부분은 주석에서 표시해 두었으며, 여기서
ChromeDriverManager().install()이 부분이 웹드라이버 매니저를 이용해 최신 버전의 크롬 드라이버를 검색하고 다운받아 설치하는 파트이다.
물론 현재 최신 버전을 사용중이라면 그대로 사용한다.
keyword_naver_tab.py
다음으로 가장 간단한 크롤링에 도전해보자.
웹페이지의 세세한 컨트롤이나 입력, 요청 등은 우선 다음 글로 미룬다.
우리의 목적은 모바일 네이버의 검색결과에서 연관검색어를 읽어오는 것이다.
무슨 말이냐면, 예를 들어 아래와 같은 부분을 가져오는 것이다.
![[Python]복붙으로 끝내는 셀레늄 크롤링](https://blog.kakaocdn.net/dn/ck6PPV/btsyQfYtM3J/NjEdJznIWJebODI7wg2A90/img.png)
굳이 모바일 페이지를 사용하는 이유는 간단한데,
데스크톱 네이버 검색 결과에는 연관검색어가 나오지 않기 때문이다.
계속해서 크롤링을 위해 필요한 부분의 CSS 셀렉터를 파악하는 것이 필요한데,
이 역시 간단하게 처리할 수 있다.
먼저 크롬 개발자도구(F12)를 띄운 뒤 Elements 항목으로 들어간다.
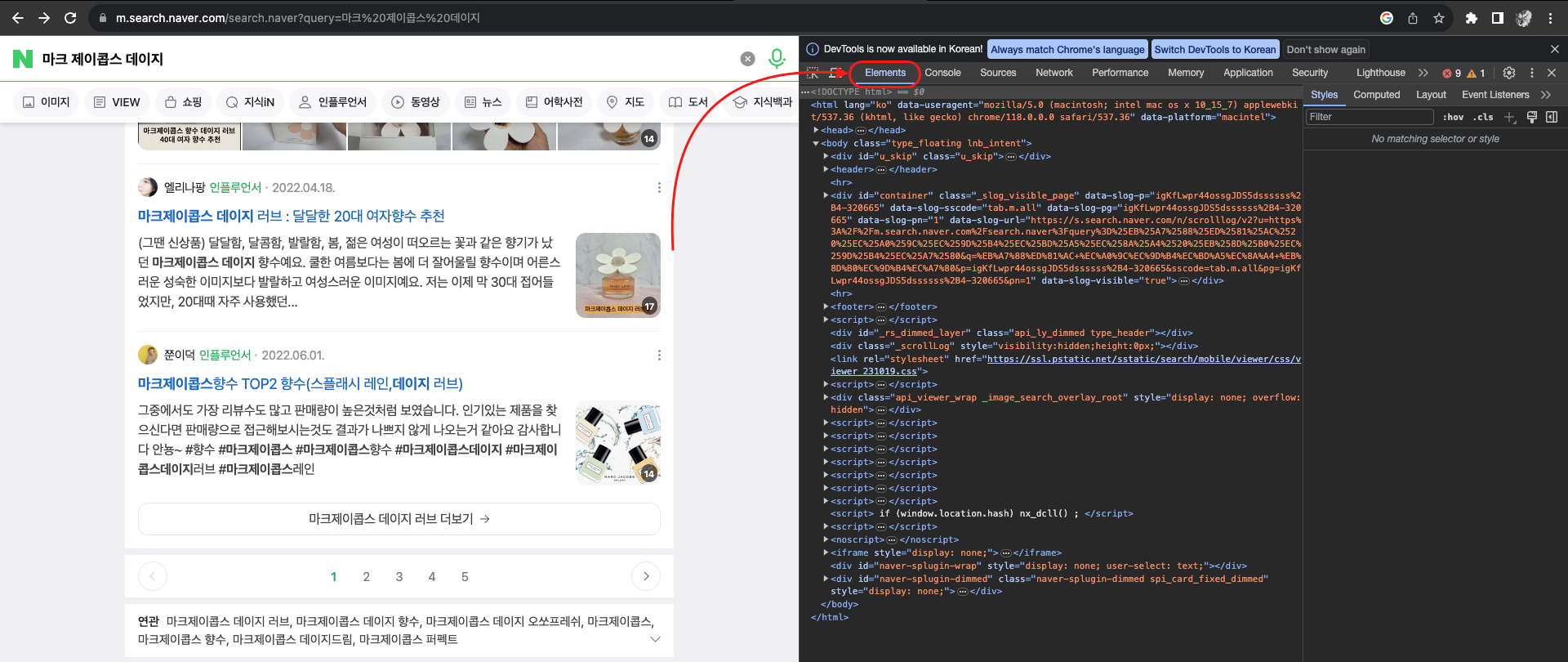
다음으로 맥북 기준 단축기(Cmd + Shift +C)를 누르거나 아래의 버튼을 눌러준다.
![[Python]복붙으로 끝내는 셀레늄 크롤링](https://blog.kakaocdn.net/dn/bn4Aya/btsyU48Mnng/N9r0N94c6s4ohNx6SCD1wk/img.png)
이후 우리가 원하는 위치에 마우스를 가져다 대면
![[Python]복붙으로 끝내는 셀레늄 크롤링](https://blog.kakaocdn.net/dn/YvkIG/btsyVZlCloe/yxd8BvHUa0Dyj1V4m43hsK/img.png)
원하는 CSS SELECTOR를 찾을 수 있다.
여기서 주의깊에 봐야 할 부분은 아래쪽에 쓰여있는 클래스 이름인데,
해당 클래스는 a 태그 안의 "clip _slog_visible"에 존재한다는 점인데, 이를 이용해 셀렉터를 선택하면 아래와 같이 된다.
a.clip._slog_visible따라서 크롤링 로직을 아래와 같이 작성하면 된다.
from webdriver_config import setup_chrome_driver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
driver = setup_chrome_driver()
query = "마크 제이콥스 데이지"
url = "https://m.search.naver.com/search.naver?query="
driver.get(url + query)
elements_texts = []
try:
# 일단 하나의 요소가 나타날 때까지 기다림
WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "a.clip._slog_visible"))
)
# 가장 처음 요소 하나만 검색
element = driver.find_element(By.CSS_SELECTOR, "a.clip._slog_visible")
print("Element: ", element.text)
except TimeoutException:
print("Timed out waiting for element to appear")
finally:
driver.quit()필요한 라이브러리와 함수를 가지고 왔고, 무엇보다 중요한 건 위에서 설정한 웹드라이버를 가져왔다는 점이다.
참고로 여기서 웹드라이버 설정 파일과 크롤링 로직 파일은 하나의 패키지 안에 있어야 한다.
그러나 계속해서 위 코드를 실행해 보면,
![[Python]복붙으로 끝내는 셀레늄 크롤링](https://blog.kakaocdn.net/dn/4zjyG/btsyU7qT4tX/HtAkUD2SqeipSzpxirY0Y1/img.png)
위와 같이 가장 앞의 요소 하나만을 가져오는 것을 확인할 수 있다.
이를 수정해 모든 검색어를 가져오려면 아래와 같이 구현하면 된다.
from webdriver_config import setup_chrome_driver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
driver = setup_chrome_driver()
query = "마크 제이콥스 데이지"
url = "https://m.search.naver.com/search.naver?query="
driver.get(url + query)
elements_texts = []
try:
# 일단 하나의 요소가 나타날 때까지 기다림
WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "a.clip._slog_visible"))
)
# 가장 처음 요소 하나만 검색
element = driver.find_element(By.CSS_SELECTOR, "a.clip._slog_visible")
print("Element: ", element.text)
# 모든 요소 검색
elements = driver.find_elements(By.CSS_SELECTOR, "a.clip._slog_visible")
# 각 요소의 텍스트 수집
for element in elements:
elements_texts.append(element.text)
# 수집된 텍스트 출력
for text in elements_texts:
print("Element Found: ", text)
except TimeoutException:
print("Timed out waiting for element to appear")
finally:
driver.quit()find_element 함수가 find_elements 함수로 바뀌었고, 결과가 문자열이 아닌 리스트로 바뀌었다.
이렇게 하면 해당 클래스에 속하는 모든 요소를 가지고 올 수 있게 된다.
![[Python]복붙으로 끝내는 셀레늄 크롤링](https://blog.kakaocdn.net/dn/uOL4k/btsyRWRIeLy/gv2pAhpK27daqnu9Ug6nO1/img.png)
keyword_google_suggestion.py
다음은 구글의 자동완성 검색어 제안 키워드이다.
이 부분은 간단히 끝내보자.
먼저 아래의 URL에 접근해 보자.
친절하게도 아래와 같이 연관 검색어만 골라서 보여준다.
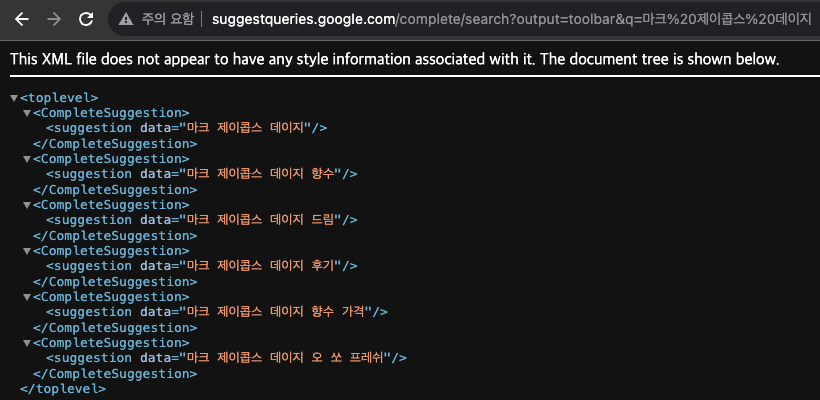
여기서 크롤링 로직을 이용해 검색어 단어만 가져오도록 설정하면 아래와 같이 된다.
from webdriver_config import setup_chrome_driver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import urllib.parse
driver = setup_chrome_driver()
query = "마크 제이콥스 데이지"
url = "http://suggestqueries.google.com/complete/search?output=toolbar&q="
driver.get(url + query)
suggested_keywords = []
try:
WebDriverWait(driver, 5).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "suggestion"))
)
elements = driver.find_elements(By.CSS_SELECTOR, "suggestion")
for element in elements:
suggested_data = element.get_attribute("data")
suggested_keywords.append(suggested_data)
for keyword in suggested_keywords:
print("Suggested keyword: ", keyword)
except TimeoutException:
print("Timed out waiting for element to appear")
finally:
driver.quit()여기선 방금 전의 로직에서 속성(Attribute)이 추가되었다.
결과는 아래와 같다.

추천 검색어와 같은 키워드를 가져오는 것을 확인할 수 있다.
이렇게 해서 이번 글에서는 주어진 페이지에서 원하는 셀렉터를 선택해 크롤링 해오는 로직을 소개했다.
이대로 복붙해서 사용하고, 셀렉터와 검색어를 이리저리 바꿔가며 연습하면 될 것이다.
만약 다음 글을 적게 된다면, 이보다 조금 더 복잡한 크롤링과 실제 웹 페이지를 조작하는 법에 대해서도 다뤄보겠다.
우선 복붙으로 끝내는 셀레늄 크롤링, 끝!
'Python > Python' 카테고리의 다른 글
| [Python]복붙으로 끝내는 셀레늄 크롤링(2) (0) | 2023.10.27 |
|---|---|
| [Python]11727번, 2×n 타일링 2 (0) | 2023.10.20 |
| [Java+Python]애너테이션 vs. 데코레이터 (0) | 2023.09.26 |
| [Python]__init__.py에 대하여 (0) | 2023.08.21 |
| [Python]전략패턴 (1) | 2023.08.15 |
| [Python]enumerate() 내장함수 (0) | 2023.05.21 |
- Total
- Today
- Yesterday
- 스트림
- RX100M5
- 동적계획법
- 파이썬
- spring
- a6000
- 알고리즘
- 세모
- Backjoon
- 여행
- 자바
- 유럽여행
- 리스트
- 백준
- BOJ
- 면접 준비
- 유럽
- 맛집
- 스프링
- 기술면접
- 칼이사
- 지지
- 세계일주
- java
- Algorithm
- 야경
- 중남미
- Python
- 세계여행
- 남미
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |