

티스토리 뷰
[면접 준비 - Database]외래 키(Foreign Key, FK)에 대하여
Vagabund.Gni 2023. 1. 2. 20:11지난 글에서 스키마 정제와 DB 정규화에 대해 정리하다 키(Key)에 대해서도 언급했다.
한 마디로 정의하자면 키란 테이블의 식별자 기능을 할 수 있는 하나 이상의 컬럼의 집합을 말하며,
조금 구체적으로는 아래와 같이 구분할 수 있다.

- 슈퍼키 - 테이블의 각 행을 유일하게 식별할 수 있는 하나 이상의 컬럼의 집합이다. 유일성을 만족한다.
- 후보키 - 슈퍼키 중에서 최소성을 만족하는 컬럼의 집합이다.
- 기본키 - 후보키 중 하나로 최소성과 유일성을 만족하는 컬럼이다. 테이블 별로 오직 하나만 지정할 수 있다.
추가로 null값을 가질 수 없고, 당연히 중복된 값을 가질 수도 없다. - 대체키 - 기본키로 선택되지 않은 후보키를 말한다. 기본키와 동일한 속성을 지니며 대체도 가능하다.
이중 보통 내가 만나는 아이는 기본키(PK)인데, 실제로도 DB 전문가가 아닌 이상 다른 키를 다룰 일은 없는 것 같다.
그럼 FK(외래키)란 무엇일까? 역시 간단하게 정리하고 넘어가자면
FK란 <참조하기 원하는 특정 테이블의 기본키>를 <자신의 테이블에 가져와 등록한 것>을 가리킨다.
그러니까 두 테이블 사이의 관계를 규정짓는 동시에 테이블을 연결해주는 중간자 역할을 한다고 볼 수 있다.
추가로 이때 참조 당하는 테이블을 부모 테이블, 참조 하는 테이블을 자식 테이블이라 부르며
당연히 부모 테이블이 자식 테이블보다 먼저 생성되어야 하고, 삭제는 그 반대 순서여야 한다.
참고로 이 관계를 그대로 내가 다루는 엔티티 클래스로 가져오면
이번엔 FK가 아닌 객체 참조를 통해 테이블 관계를 결정하게 된다.
하지만 쉽게 예상할 수 있듯이 테이블 개수가 조금만 늘어나도 금방 복잡한 매핑관계가 발생하게 되며,
이리저리 얽혀있는 FK는 개발의 자유도를 조금 낮추는 느낌이 드는 것도 사실이다.
그렇다면 FK를 사용해서 얻을 수 있는 장점은 무엇일까?
Data Integrity
데이터 무결성. 어쩐지 숭고한 느낌이 드는 단어다.
여러 자료를 읽어보니 FK의 시작과 끝은 참조 무결성(Referential Integrity)이 보장하는 데이터 무결성이라는 생각이 들었다.
데이터 무결성이란 말 그대로 DB에 대한 신뢰도를 가리킨다.
무결성이 깨진 DB는 더이상 신뢰할 수 없게 되니까.
이 부분에서 예를 들면 FK는 다음과 같은 기능을 한다.
위와 같이 수업 테이블을 학생 테이블이 FK를 이용해 참조하고 있다고 치자.
만약 수학 수업의 가격을 5000원 인상해야 한다고 할 때, 수업 테이블에서 수강료를 고친 뒤
학생 테이블에서 하나하나 값을 고치다 실수라도 하면 같은 수업을 다른 가격에 듣는 상황이 생길 가능성이 생긴다.
그러니까, 테이블이 무결성에서 어긋난 틀린 값을 가지게 될 가능성이 생긴다는 뜻이다.
FK와 그 제약조건은 위와 같은 상황을 미연에 방지한다.
데이터 수정 혹은 삭제시 FK가 설정되어 있다면 아래와 같은 제약조건을 사용할 수 있다.
- CASCADE - 부모 테이블의 데이터 수정/삭제 시 자식 테이블의 데이터에 반영(부모 테이블 종속)
- RESTRICT - 자식 테이블에 데이터가 존재한다면 부모 테이블의 해당 키 데이터는 수정/삭제 불가(자식 테이블 종속)
- SET NULL - 부모 테이블의 데이터 수정/삭제시 자식 테이블의 데이터는 NULL로 변경
- SET DEFAULT - 부모 테이블의 데이터 수정/삭제시 자식 테이블의 데이터는 필드 기본값으로 변경
- NO ACTION - 위의 종속성 중 어느 것도 적용하지 않는다.
ERD
스키마를 통한 DB 다이어그램에서 테이블간의 관계를 한눈에 파악할 수 있다.
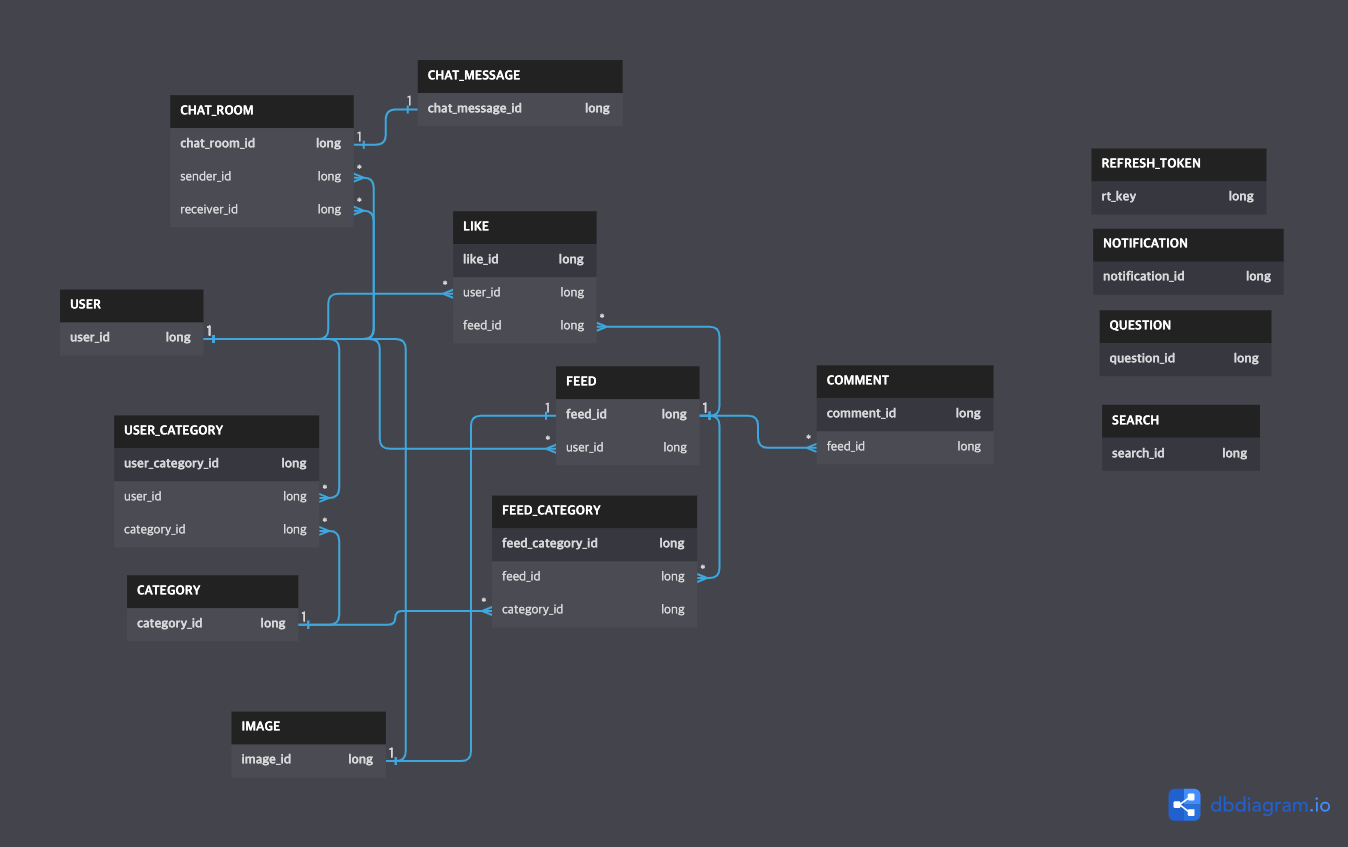
FK가 없다면 손으로 참조관계를 그리거나 코드를 보면서 따라가야 할 것이다.
당연히 사람이 실수할 여지가 커지게 된다.
여기까지 보면 당연히 써야하는 것처럼 느껴지는데, 검색하다 보니 의외로 실무에서 사용하지 않는 곳도 있다고 한다.
마지막으로 그 이유를 간략하게 정리하자.
No Foreign Key
- 성능 - 데이터 무결성을 지키기 위해 부모 테이블을 확인하는 등의 오버헤드가 생긴다. 이는 특히 데이터 웨어하우스
(분석 가능한 형태로 변환된 데이터 저장소)와 같이 대량의 데이터를 Transactional 하게 다룰 필요가 없는 곳에
적용된다. - 레거시 데이터 - 레거시 데이터의 정합성이 이미 깨져서 편입이 불가능할 경우
- 고수준 프레임워크 - ORM을 사용하는 Ruby on Rails 같은 프레임워크는 간단하게 참조 무결성을 보장한다.
- DB 사이의 관계 - 물리적으로 별개의 DB나 엔진의 경우 경계를 넘어 키를 생성하는 것이 가능하지 않다.
실제로는 DW수준의 대량의 데이터가 아니고선 성능 저하는 체감되지 않는다고 한다.
이렇게 이유를 모아놓고 보니 오히려 진짜 불가피한 상황이 아니고서는 꼭 FK를 설정해서 사용해야 할 것 같다.
'Development > Technical Interview' 카테고리의 다른 글
| [Security]RBAC vs. ABAC (0) | 2023.03.05 |
|---|---|
| [면접 준비 - Network]대량의 트래픽에 대한 대처방법 (0) | 2023.02.28 |
| [면접 준비 - Java]String vs. String Buffer vs. String Builder (0) | 2023.01.18 |
| [면접 준비 - CS]컴퓨터 부팅 과정 (1) | 2022.12.29 |
| [면접 준비 - Network]웹 애플리케이션의 작동 흐름 (6) | 2022.12.28 |
| [면접 준비 - Database]스키마 정제, DB 정규화 (3) | 2022.12.28 |
- Total
- Today
- Yesterday
- 여행
- 세계일주
- 세모
- RX100M5
- 야경
- 유럽
- 맛집
- Python
- 자바
- 리스트
- 남미
- 지지
- java
- Backjoon
- 세계여행
- 면접 준비
- 스트림
- 중남미
- 스프링
- Algorithm
- a6000
- BOJ
- 칼이사
- 기술면접
- 유럽여행
- 파이썬
- 알고리즘
- spring
- 동적계획법
- 백준
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |