
티스토리 뷰
[Kafka]Kafka: a Distributed Messaging System for Log Processing
Vagabund.Gni 2023. 9. 17. 21:57목차
https://pages.cs.wisc.edu/~akella/CS744/F17/838-CloudPapers/Kafka.pdf
Kafka: 로그 처리를 위한 분산 메시징 시스템
이 논문은 카프카가 처음 만들어진 후(2011) 발간된 첫 논문이다.
정확하게는 논문이라기 보다는 내부 기술문서의 형태를 가지는데, 기념할만한 문서라 생각해서 읽고 정리해 보았다
당연히 전문 번역은 아니고 요약에 가깝다.
Abstract
데이터 파이프라인에서 로그 처리는 중요한 구성요소가 되었다.
큰 용량의 데이터를 낮은 지연시간으로 수집하고 전달하기 위한 분산 메시징 시스템으로써 카프카를 소개한다.
이 시스템은 기존의 로그 집계기와 메시징 시스템의 아이디어를 통합하고, 오프라인/온라인 메시지 소비에 모두 적합하다.
카프카는 효율성과 확장성을 위해 몇 가지 비전통적이지만 실용적인 설계를 선택했는데,
실험 결과에서 카프카는 두 개의 유명한 메시징 시스템과 비교했을 때 우수한 성능을 보였다.
실제로도 매일 수백 기가바이트의 데이터를 처리하는 데 사용되고 있다.
General Terms: 관리, 성능, 디자인, 실험
Keywords: 메시징, 분산, 로그 처리, 처리량, 온라인
1. Introduction
일정 이상 규모의 인터넷 회사에서는 대량의 로그 데이터가 생성된다.
이는 일반적으로 사용자 활동과 시스템 지표 등을 포함한다.
이 데이터는 과거에는 주로 분석 및 추적 목적으로 사용되었으나,
최근의 트렌드는 이를 생상 데이터 파이프라인의 일부가 되었다.
이는 검색 관련성 향상, 추천 시스템, 광고 타겟팅, 보안, 뉴스피드 등에 로그 데이터가 직접적으로 활용되고 있음을 가리킨다.
이와 같은 로그 데이터의 실시간 사용은 데이터 시스템에 새로운 도전을 제기한다.
로그 데이터는 '실제' 데이터보다 몇 배나 크고, 예를 들면 검색, 추천, 광고는 세분화된 클릭률을 계산해야 하며
이는 매우 많은 양의 로그를 생성하게 된다. 차이나 모바일과 페이스북은 매일 수 TB의 로그 데이터를 수집하고 있다.
초기의 로그 데이터 처리 시스템은 대부분 생산 서버에서 로그 파일을 물리적으로 스크래핑해 분석했다.
최근(2011)에는 여러 집계기가 개발되었으나 이 시스템은 주로 로그 데이터를 데이터 웨어하우스나 하둡으로 로드해
오프라인으로 분석할 목적으로 사용되었다.
링크드인에서는 이와 달리 실시간 애플리케이션을 최소의 지연시간으로 지원해야 하는 필요성을 느꼈다.
따라서 로그 집계기와 메시징 시스템의 이점을 결합한 새로운 메시징 시스템 카프카를 개발했다.
이는 분산과 확장성, 그리고 높은 처리량을 가진 메시징 시스템이며 API를 제공해 실시간 로그 이벤트 소비가 가능하다.
카프카는 링크드인에서 6개월 이상 성공적으로 사용되었으며, 하나의 소프트웨어로 온/오프라인 모두를 처리할 수 있어
인프라가 단순화되었다. 논문의 2부는 전통적인 메시징 시스템과 로그 집계기를 살펴보고,
3부에서는 카프카 아키텍처와 주요 디자인 원칙에 대해 설명한 뒤
4부에서는 링크드인에서의 카프카 배포와 결과에 대해 설명한다.
2. Related Work
기존 메시징 시스템이 로그처리에 적합하지 않은 이유는 다음과 같다.
- 기업용 시스템에서 제공하는 기능과의 불일치
- 많은 시스템이 처리량을 주된 제약 사항으로 고려하지 않았다.
- 분산에 대한 지원이 약하다.
- 메시지가 거의 즉시 소비되기 때문에 소비되지 않은 메시지 큐의 크기가 작다.
- 메시지가 축적되도록 허용하면 성능이 크게 저하된다.
페이스북과 야후가 만들어낸 시스템은 "푸시" 모델을 사용하기 때문에 실시간 처리에 한계가 있다.
링크드인에서는 "풀" 모델이 적합하다고 판단해 각 소비자가 효율적으로 데이터를 처리할 수 있도록 한다.
3. Kafka Architecture and Design Principles
이와 같은 시스템의 한계를 극복하기 위해 새로운 메시징 기반 로그 집계기 카프카를 개발했다.
카프카에서는 특정 유형의 메시지 스트림이 '토픽'으로 정의된다.
프로듀서는 토픽에 메시지를 발행(Publish)할 수 있으며 발행된 메시지는 '브로커' 라고 하는 서버에 저장된다.
컨슈머는 브로커에서 하나 이상의 토픽을 구독하고, 브로커로부터 데이터를 '끌어와'
구독한 메시지를 소비할 수 있다.
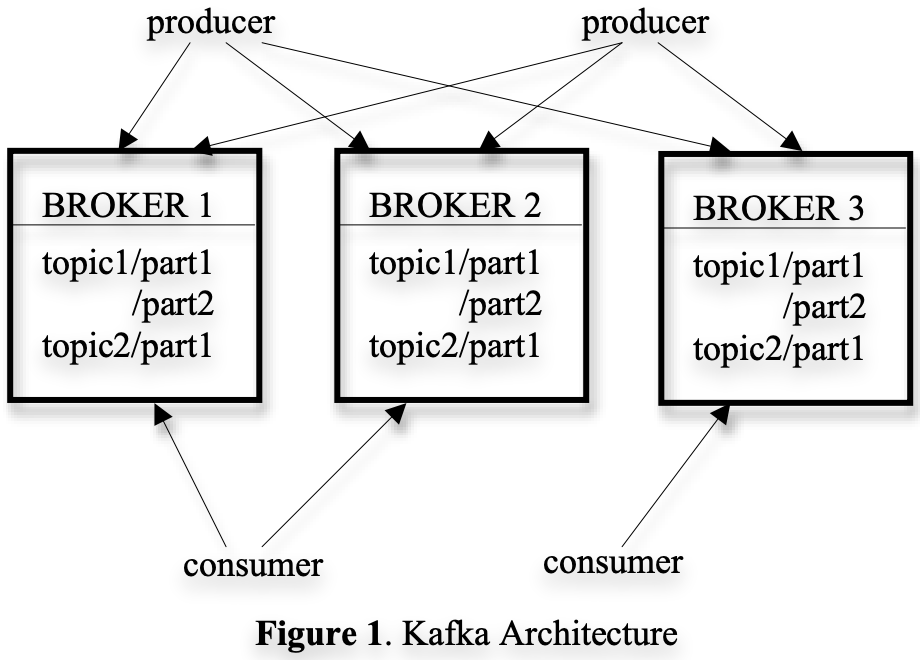
카프카의 전체 아키텍처는 분산형이며, 일반적으로 여러 브로커로 구성된다.
부하 분산을 위해 토픽은 다시 여러 파티션으로 나뉘며, 각 브로커는 하나 이상의 파티션을 저장한다.
이로 인해 여러 프로듀서와 컨슈머가 동시에 메시지를 게시 및 구독할 수 있다.
이는 메시징을 단순하게 하며 매우 효율적이고 확장성 높은 로그 처리 시스템을 제공한다.
특히 다양한 소비 모델을 지원하여 여러 앱에 각각 적합하게 구성할 수 있다.
3.1 Efficiency on a Single Partition
카프카 개발자들은 효율적인 시스템을 위해 몇 가지 결정을 내렸다.
Simple storage
카프카는 아주 간단한 저장소 레이아웃을 가지고 있다.
토픽의 각 파티션은 논리적인 로그에 해당하고, 이 로그는 비슷한 크기의 세그먼트 파일로 구현된다.
메시지가 발행될 때마다 브로커는 마지막 세그먼트 파일에 메시지를 추가하는데,
성능을 높이기 위해 일정 수의 메시지가 발행되거나 일정 시간이 지난 후에 세그먼트 파일을 디스크로 플러시 한다.
여기서 메시지에는 명시적인 ID가 따로 존재하지 않으며, 로그 내의 논리적 오프셋으로 지정된다.
메시지는 플러시 된 후에만 컨슈머에게 노출되며,
컨슈머는 특정 파티션의 메시지를 순차적으로 소비한다.
아래 그림은 카프카 로그의 레이아웃과 인메모리 색인을 나타낸다.

Efficient transfer
카프카는 메시지를 명시적으로 메모리에 캐싱하지 않고 기본 파일 시스템 페이지 캐시에 의존한다.
이는 가비지 컬렉션에 있어 아주 작은 오버헤드를 가지도록 하며,
브로커 프로세스가 재시작되더라도 웜 캐시가 유지되는 이점을 가진다.
Stateless broker
대부분의 메시징 시스템과 달리, 카프카에서는 각 컨슈머의 데이터 소비량이 브로커에 의해 유지되지 않는다.
그 대신 컨슈머에 의해 유지되는데, 이런 설계는 브로커의 복잡성과 오버헤드를 크게 줄이는 효과가 있다.
다만 메시지를 삭제하기 어렵다는 문제점이 생기는데, 카프카는 이 문제를 해결하기 위해
브로커에서 일정 기간 동안 보관된 경우 자동으로 삭제되도록 정책을 사용한다.
이 설계의 다른 부가적 이점은, 컨슈머가 데이터를 다시 소비할 수 있다는 점이다.
앱의 로직의 오류가 있으면 오류를 수정한 후 특정 메시지를 다시 소비할 수 있다는 뜻이다.
또한 이런 방식은 푸시 방식보다는 풀 방식에서 훨씬 쉽게 지원된다.
이와 같은 특징을 바탕으로 카프카는 대용량 데이터를 효과적으로 처리할 수 있게 된다.
3.2 Distributed Coordination
분산 설정에서 프로듀서와 컨슈머가 어떻게 작동하는지 설명한다.
각 프로듀서는 메시지를 무작위로 선택한 파티션 혹은 파티셔닝 키와 함수에 의해 시멘틱 하게 정해진 파티션에
발행할 수 있다. 이 섹션에서는 컨슈머와 브로커 사이의 상호작용에 초점을 맞춘다.
카프카에는 '컨슈머 그룹'이라는 개념이 있다. 같은 그룹은 구독한 토픽의 메시지를 공동으로 소비하며,
다른 그룹은 독립적으로 작동한다. 여기서 목표는 브로커에 저장된 메시지를 컨슈머 사이에 고르게 분배하는 것이며,
이를 위해 많은 오버헤드를 도입하지 않는 것이다.
두 가지 결정은 다음과 같다.
- 파티션 병렬성: 한 파티션의 모든 메시지는 한 번에 하나의 컨슈머만 소비할 수 있다.
- '마스터'노드 없는 분산 방식: 컨슈머는 주키퍼(Zookeeper)를 사용해 분산 방식으로 조정한다.
위와 같은 결정이 분산환경에서의 카프카 동작을 효율적으로 만든다.
주키퍼는 매우 간단한 API를 가진다. 경로 생성, 값 설정, 값 읽기, 경로 삭제, 자식 경로 나열 등이 있다.
또한 watcher를 등록해 경로의 자식이나 값이 변경되면 알림을 받거나
경로를 일시적(혹은 영구적)으로 생성할 수 있으며 데이터를 여러 서버에 복제하는 등의 고급 기능도 가지고 있다.
카프카는 이 주키퍼를 다음과 같은 작업에 사용한다.
- 브로커와 컨슈머의 추가 및 제거 감지
- 위 이벤트 발생 시 각 컨슈머에서 리밸런싱 프로세스 트리거
- 각 파티션의 소비된 오프셋을 추적하고 소비관계 유지
구체적으로는 각 브로커나 컨슈머가 시작될 때 그 정보를 주키퍼의 브로커 혹은 컨슈머 레포지토리에 저장한다.
이는 네트워크 정보와 토픽, 파티션 정보를 관리하는 데 쓰인다.
이어서 각 컨슈머 그룹은 주키퍼에서 소유권 레지스트리와 오프셋 레지스트리를 관리하며,
이를 통해 어느 컨슈머가 어느 파티션을 소비하고 있는지, 각 파티션의 마지막 오프셋이 무엇인지 추적할 수 있다.
주키퍼에 의해 생성된 경로 중 브로커, 컨슈머, 소유권 레지스트리는 일시적이며 오프셋 레지스트리는 영구적이다.
각 컨슈머는 브로커, 컨슈머 레지스트리에 주키퍼 Watcher를 등록해
브로커 세트나 컨슈머 그룹에 변화가 생기면 알림을 받는다.
처음 시작하는 시점이나 브로커/컨슈머 변화에 대해 알림을 받으면 컨슈머는 새로 소비해야 할 파티션의
부분 집합을 결정하기 위한 리밸런신 프로세스를 시작한다. 이 과정은 아래의 알고리즘에서 설명된다.

컨슈머는 소유할 새로운 파티션을 결정한 뒤 소유권 레지스트리에 새로운 컨슈머로 등록한다.
이후 저장된 오프셋으로부터 데이터를 불러오고, 불러올 때마다 오프셋을 업데이트한다.
하나의 그룹에 여러 컨슈머가 있을 경우엔 리밸런싱 프로세스는 몇 번의 재시도를 거치기도 한다.
새로운 컨슈머 그룹이 생성될 때, 오프셋 레지스트리는 비어있으므로, 컨슈머는 브로커에서 제공하는 API를 이용해
각 구독된 파티션에서 사용 가능한 가장 작은, 혹은 가장 큰 오프셋에서 시작하게 된다.
3.3 Delivery Guarantees
카프카는 일반적으로 한 번은 메시지가 전달될 것을 보장한다. 그러나 여러 가지 이유로 컨슈머 프로세스가
중복 메시지를 받을 가능성이 있기 때문에, 오프셋이나 고유 키를 사용해 중복 제거 로직을 추가해야 한다.
이는 보통 사용되는 2단계 커밋보다 더 비용 효율적인 접근 방법이다.
카프카는 단일 파티션에서 오는 메시지가 컨슈머에게 순서대로 전달될 것을 보장한다.
하지만 다른 파티션에서 오는 메시지의 순서에 대해서는 보장하지 않는다.
로그 손상을 피하기 위해 카프카는 로그의 각 메시지에 대한 CRC를 저장한다.
여기서 CRC란 Cyclic Redundancy Check의 약자로, 데이터 전송 시 오류를 검출하기 위한 방법 중 하나이다.
브로커에서 오류가 발생하면 카프카는 이를 바탕으로 복구 프로세스를 실행한다.
브로커가 다운되면 그 안에 저장된, 아직 소비되지 않은 메시지는 소실된다.
앞으로 메시지를 여러 브로커에 중복 저장하는 복제 기능을 추가할 예정이다(이 부분은 스터디 후 보강하겠음).
4. Kafka Usage at LinkedIn
이 섹션에서는 링크드인에서 카프카를 실제로 어떻게 사용하는지 설명한다.
아래의 그림 3은 배포 버전을 단순화한 것이다.
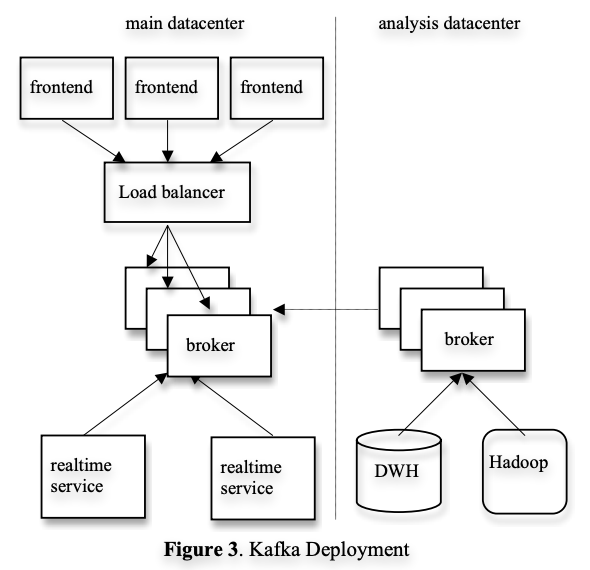
서비스가 실행되는 데이터센터마다 하나의 카프카 클러스터가 있고,
프론트엔드에서 생성한 로그 데이터를 카프카 브로커로 배치로 발행한다.
이 요청은 다시 로드 밸런서를 통해 브로커들에게 균등하게 분배된다.
또한 오프라인 분석을 위한 별도의 데이터센터에도 카프카 클러스터를 배포하고 있으며,
지리적으로 하둡 클러스터와 다른 데이터 웨어하우스 인프라 가까이 위치한다.
이는 하둡과 데이터 웨어하우스로 데이터를 불러와 분석하고 리포팅하기 위함이며,
프로토타이핑과 애드혹 쿼리에도 사용되며 종단 간 지연 시간은 평균 10초로 요구사항을 충족한다.
데이터의 정확성을 보장하기 위해 각 메시지에는 타임스탬프와 서버 이름이 포함되며,
모니터링 이벤트를 통해 데이터 손실이 없는지 검증한다.
또한 Avro를 직렬화 프로토콜로 사용하며, 스키마 레지스트리 서비스를 통해 프로듀서와 컨슈머 간의 호환성을 보장한다.
5. Experimental Results
이 섹션에서는 실험을 통해 카프카의 성능을 아파치 액티브 MQ v5.4, JMS 구현체, 그리고 래빗MQ v2.4와 비교한다.
실험은 두 대의 리눅스 기계에서 실행되었으며, 각 기계는 8개의 2GHz코어, 16GB 메모리, RAID10을 지원하는
6개의 디스크로 구성되어 있고 두 기계는 1Gb 네트워크 링크로 연결되어 있다.
Producer Test

카프카는 나머지 두 MQ와 다르게 메시지를 일괄 처리하는 쉬운 방법이 있기 때문에
브로커로부터의 확인대기 없이 메시지를 빠르게 전송, 훨씬 높은 처리량을 보였다.
특히 50개의 메시지 크기의 일괄 처리는 처리량의 단위를 거의 하나 높였다.
Consumer Test

카프카 컨슈머는 저장형식의 효율성, 브로커의 디스크 쓰기 활동의 부재, 그리고 sendfile API의 사용을 통해
다른 두 MQ보다 4배 이상 높은 처리량을 보였다. 이는 전문화된 시스템이 얼마나 더 높은 성능을 낼 수 있는지 보여준다.
6. Conclusion and Future Works
카프카라는 새로운 시스템은 대량의 로그 데이터 스트림을 처리하기 위해 설계되었다.
메시징 시스템과 같이 카프카는 앱이 자체 속도로 데이터를 소비하고 필요할 때마다 소비를 되감을 수 있는
pull-based consumption 모델을 사용한다.
로그 처리에 중점을 둠으로써 카프카는 기존 메시징 시스템보다 훨씬 높은 처리량을 달성하며,
분산 지원을 통하여 스케일 아웃이 가능하다.
이 카프카는 현재 링크드인의 온/오프라인 앱에서 성공적으로 사용되고 있다.
이후의 추구 방향은 다음과 같다.
- 다중 브로커 간에 메시지의 내장 복제를 추가하여 복구할 수 없는 기계 실패의 경우에도 데이터 내구성과 가용성을 보장
- 스트림 처리 기능 추가
카프카의 개발 의도와 처리량 및 확장성,
그리고 초창기부터 사용된 Avro와 스키마 레지스트리의 역할에 대해 조금 더 명확하게 알 수 있었다.
아래의 카프카 공식 홈페이지에 가면 관련된 책과 페이퍼들을 확인할 수 있으니
더 궁금하다면 읽어보아도 좋을 것 같다.
https://kafka.apache.org/books-and-papers
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
끝!
'Development > Paper Review' 카테고리의 다른 글
| [MSA+DDD]DDD는 MSA의 최적 모듈화를 찾는데 도움을 주는가?(10.1109/ACCESS.2021.3060895) (0) | 2023.04.22 |
|---|---|
| [MSA]Monolithic vs. MSA: 성능과 확장성 평가(10.1109/ACCESS.2022.3152803) (8) | 2023.04.10 |
| [MSA]뜬금 논문 리뷰 - j.jss.2022.111521 (0) | 2023.03.31 |
- Total
- Today
- Yesterday
- 면접 준비
- BOJ
- 칼이사
- Algorithm
- 맛집
- RX100M5
- 파이썬
- java
- 알고리즘
- 동적계획법
- 세모
- 남미
- Backjoon
- 야경
- 기술면접
- 지지
- 유럽
- Python
- 세계일주
- 세계여행
- 백준
- 여행
- 스트림
- spring
- 중남미
- 스프링
- 자바
- 유럽여행
- a6000
- 리스트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |