

티스토리 뷰
목차
지난 글에서는 객체 탐지의 필수 평가요소인
객체 탐지(Object Detection)에서는 프리시전(Precision), 리콜(Recall), mAP 등에 대해 알아보았다.
그러나 아직 넘어야 할 선이 있는데, 그것이 바로 후처리 과정!
그 과정에서 쓰이는 알고리즘이 바로 NMS(Non-Maximum Suppression) 알고리즘이다.
선요약하고 들어가자면, 이 알고리즘은
모델이 탐지한 결과 중 겹치는 박스들 중 가장 좋은 것만 남기고 나머지를 제거하는 과정이다.
이어지는 글에서는 적당한 예시를 들어, NMS가 왜 필요하고 어떻게 동작하는지 간단히 살펴본다.
객체 탐지 모델이 주는 결과는 어떤 모습일까?
객체 탐지 모델(YOLO, Faster R-CNN 등)이 이미지를 보고 예측을 하면, 다음과 같은 정보들이 나온다.
- 박스 좌표 (x1, y1, x2, y2) → 왼쪽 위 모서리, 오른쪽 아래 모서리 좌표
- 객체 클래스 → 강아지, 고양이 등
- 신뢰도(Confidence Score) → 0.9, 0.8 등
뭐가 문제일까?

모델은 같은 객체에 대해서 여러 개의 박스를 그려내는 경우가 많다.
특히, 아래와 같은 경우가 흔하다.
- 강아지 한 마리를 탐지했는데 비슷한 위치에 겹쳐서 박스가 여러 개 나옴
- 조금씩 위치와 크기가 다른 박스들이 중복해서 검출됨
결국, 같은 강아지를 여러 번 탐지한 것처럼 보이게 된다.
이러면 FP(False Positive)가 늘어나서 성능 평가에도 문제가 생기고, 출력 결과도 지저분해진다.
객체 탐지 평가 지표: Precision, Recall, mAP, F1 Score 완전 이해하기
객체 탐지 평가 지표: Precision, Recall, mAP, F1 Score 완전 이해하기
목차 지난 글에서 컴퓨터 비전과 객체 인식에 대한 입문의 입문.. 정도 되는 개념을 알아보았다. 하지만 들을땐 그런가 보다 하고 들었는데 생각할수록 각종 지표의 개념과 의미가 헷갈려서..
gnidinger.tistory.com
그래서 등장한 것이 바로 NMS(Non-Maximum Suppression)이다.
NMS가 하는 일
NMS는 중복된 박스들 중에서 가장 좋은 것 하나만 남기는 역할을 한다.
핵심 아이디어는 이렇다.
- 신뢰도(Confidence)가 높은 박스를 우선적으로 선택한다.
- 선택한 박스와 겹치는 다른 박스들은 제거한다.
이 과정을 반복하면서 최종적으로 겹치지 않는 최선의 박스들만 남게 된다.
NMS 동작 과정: 예시
상황 설정
고양이가 한 마리 있는 이미지가 있다.
모델이 아래와 같이 겹치는 박스 4개를 예측했다고 해보자.
| 박스 번호 | 좌표(x1, y1, x2, y2) | 신뢰도(Confidence) |
| 박스 1 | (50, 50, 150, 150) | 0.9 |
| 박스 2 | (55, 55, 155, 155) | 0.85 |
| 박스 3 | (48, 48, 148, 148) | 0.7 |
| 박스 4 | (200, 200, 300, 300) | 0.6 (다른 위치에 있음) |
박스 1, 2, 3은 거의 똑같은 위치라서 강아지 1마리를 가리키는 것이다.
박스 4만 멀리 떨어진 엉뚱한 위치다.
Step 1: 신뢰도 순서대로 정렬
신뢰도(Confidence)가 높은 순서대로 정렬한다.
- 박스 1 (0.9)
- 박스 2 (0.85)
- 박스 3 (0.7)
- 박스 4 (0.6)
Step 2: 가장 높은 신뢰도 박스 선택 → 박스 1
박스 1이 가장 높으므로 이걸 선택한다.
Step 3: IoU(Intersection over Union) 계산해서 겹치는 박스 제거
IoU란?
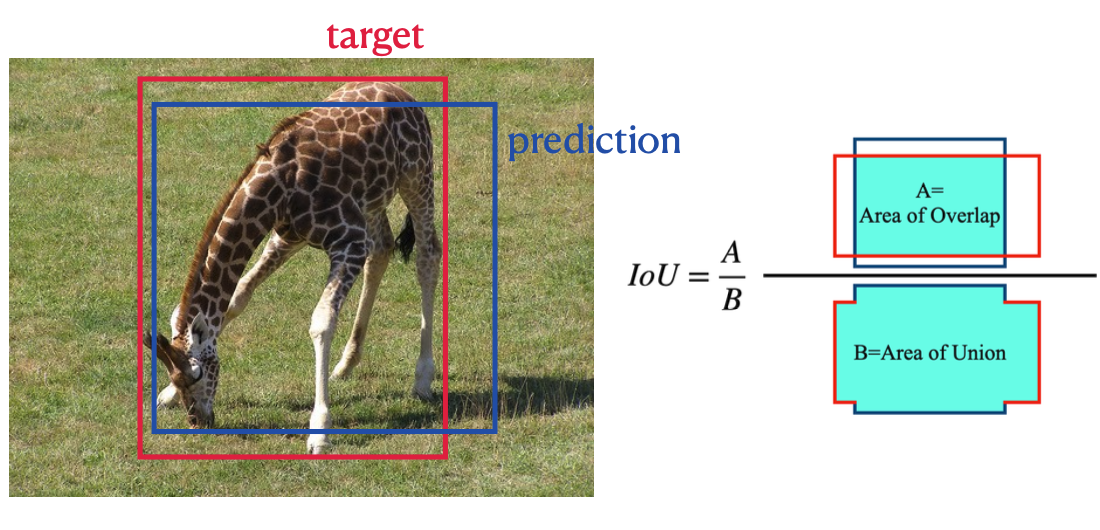

한 마디로 말하자면 모델이 그린 박스와 실제 정답 박스가 겹치는 정도이다.
- 박스 1과 박스 2의 IoU 계산 → 거의 똑같은 위치라서 IoU = 0.9 이상일 것이다.
- 박스 1과 박스 3의 IoU 계산 → 이것도 비슷하니까 IoU = 0.85 정도일 것이다.
보통 NMS에서는 IoU 임계값(threshold)을 0.5~0.7 사이로 설정한다.
여기서는 IoU 임계값을 0.5로 설정했다고 가정하자.
- 박스 1과 박스 2 → IoU 0.9 → 0.5보다 크다 → 제거
- 박스 1과 박스 3 → IoU 0.85 → 0.5보다 크다 → 제거
Step 4: 남은 박스 중 다음 신뢰도 높은 것 선택 → 박스 4
박스 2, 박스 3은 제거되었고 박스 4만 남았다.
- 박스 1과 박스 4의 IoU 계산 → 완전히 멀리 떨어져 있으므로 IoU = 0이다.
IoU < 0.5니까 남긴다.
최종 결과
- 선택된 박스 1 → 강아지 위치 정확
- 선택된 박스 4 → 멀리 떨어진 박스지만 남음
최종적으로 2개의 박스만 남는다.
왜 NMS가 중요할까?
- FP(False Positive)를 줄인다.
같은 객체에 대해 여러 번 중복 탐지한 것을 제거하기 때문에, 정확도가 올라간다. - 결과가 깔끔해진다.
중복 박스가 많으면 화면에 박스가 난잡해진다.
NMS를 적용하면 가장 좋은 박스만 남기므로 시각적으로도 보기 좋다. - 모든 객체 탐지 모델에서 필수적으로 사용된다.
YOLO, Faster R-CNN, SSD 등 대부분의 탐지 모델은 NMS를 후처리에 사용한다.
NMS의 단점
- 가까이 붙어있는 객체를 구분 못하는 경우가 있다.
예: 나란히 앉아있는 두 마리 고양이
→ NMS가 너무 공격적으로 겹치는 것들을 제거하면, 한 마리만 있는 것처럼 처리될 수 있다. - 최적의 IoU 임계값 설정이 중요하다.
→ IoU 임계값이 너무 낮으면 너무 많은 박스를 지우고,
→ 너무 높으면 중복 박스를 다 못 지울 수 있다.
소프트 NMS(Soft-NMS): 개선 방법
NMS는 아예 겹치면 무조건 제거한다.
소프트 NMS(Soft-NMS)는 완전히 제거하지 않고 신뢰도(Confidence)를 점진적으로 줄이는 방식이다.
- 겹치는 박스라도 완전히 제거하지 않고, 신뢰도를 낮춰서 남긴다.
이렇게 하면 가까이 붙어있는 객체를 놓칠 확률이 줄어든다.
핵심 요약
| 항목 | 설명 |
| NMS | 겹치는 박스 중 가장 좋은 것만 남기고 나머지는 제거 |
| IoU | 박스 겹침 정도 (0~1 사이 값) |
| 임계값 | 보통 0.5~0.7 |
| Soft-NMS | 제거 대신 신뢰도를 낮추는 방식 |
객체 탐지에서는 중복 박스 제거가 필수다.
NMS는 이를 해결하기 위한 가장 기본적인 방법이다.
실제로 모델 성능보다도 후처리(NMS)를 잘 조절하는 것이 결과에 큰 영향을 미친다는 점을 기억하자.
'ML+DL > Vision AI' 카테고리의 다른 글
| 활성화 함수와는 다르다! 활성화 함수와는! 소프트맥스(Softmax)함수 (0) | 2025.03.14 |
|---|---|
| CNN에서 활성화 함수가 여러번 적용되는 이유 (0) | 2025.03.11 |
| 비전 인공지능에서 백본(Backbone)이란? (0) | 2025.02.21 |
| 객체 탐지 평가 지표: Precision, Recall, mAP, F1 Score 완전 이해하기 (0) | 2025.02.18 |
| 컴퓨터 비전과 객체 인식: YOLO 모델과 평가 지표에 대한 이해 (0) | 2025.01.21 |
| CNN의 한계와 어텐션 기법, 그리고 비전 트랜스포머 모델 (0) | 2025.01.15 |
- Total
- Today
- Yesterday
- spring
- Backjoon
- 맛집
- a6000
- 면접 준비
- 유럽
- 자바
- 칼이사
- 세계여행
- 세계일주
- 알고리즘
- 지지
- 중남미
- 세모
- BOJ
- Algorithm
- Python
- 스프링
- 여행
- 스트림
- 동적계획법
- 파이썬
- 유럽여행
- 기술면접
- 백준
- 야경
- java
- RX100M5
- 남미
- 리스트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |