

티스토리 뷰
지난 글에선 기초적인 MLP를 이용한 집값 예측 모델을 만들어 보았다.
이번 글에서는 컴퓨터 비전 쪽으로 넘어와서 CNN을 이용해 CIFAR-10 데이터셋을 학습하고,
테스트 데이터를 분류하는 코드를 구현해 보겠다.
참고로 CIFAR-10은 10가지 클래스(예: 자동차, 개, 새 등)의 컬러 이미지를 포함한 데이터셋이며,
딥러닝에서 CNN은 이미지 데이터의 특성을 잘 학습하기 때문에 이미지 분류 문제에 자주 사용된다.
사실 구현이라기 보단 학습 코드를 뜯어보는 것에 가깝기 때문에, 별 새로운 내용은 없다.
선 요약
먼저 오늘 뜯어볼 코드와 결과는 다음과 같다:
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from tqdm import trange
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
trainloader = DataLoader(trainset, batch_size=32, shuffle=True)
testset = datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
testloader = DataLoader(testset, batch_size=32, shuffle=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"{device} is available.")
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120), nn.ReLU(), nn.Linear(120, 10)
)
def forward(self, x):
x = self.feature_extraction(x)
x = x.view(-1, 16 * 5 * 5)
x = self.classifier(x)
return x
net = CNN().to(device)
print(net)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
loss_ = []
n = len(trainloader)
num_epochs = 10
pbar = trange(num_epochs)
for epoch in pbar:
running_loss = 0.0
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
l = running_loss / n
loss_.append(l)
pbar.set_postfix({"epoch": epoch + 1, "loss": l})
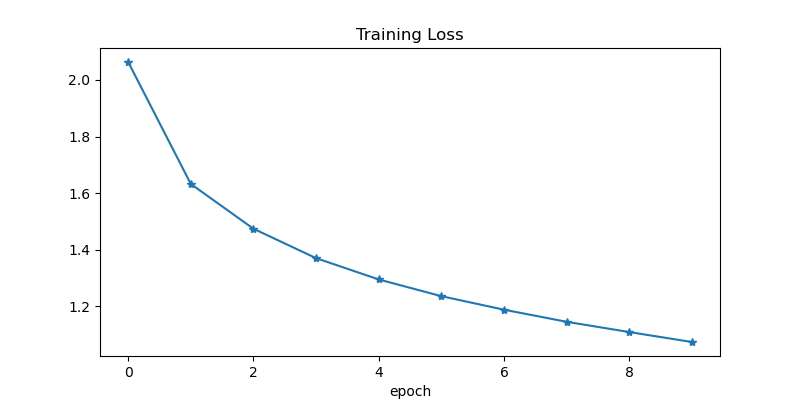
plt.figure(figsize=(8, 4))
plt.plot(loss_, "-*")
plt.title("Training Loss")
plt.xlabel("epoch")
plt.show()
correct = 0
total = 0
with torch.no_grad():
net.eval()
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(
"Accuracy of the network on the 10000 test images: %d %%" % (100 * correct / total)
)
Accuracy of the network on the 10000 test images: 61 %계속해서 핵심 워크플로우는 다음과 같다.
- 데이터 준비
- CIFAR-10 데이터셋을 다운로드하고, 이미지를 텐서로 변환한 뒤 정규화한다.
- 학습용 데이터는 shuffle=True로 배치 단위로 로드한다.
- 모델 정의
- 합성곱 신경망(CNN) 구조를 정의하여 이미지 특징을 추출(feature_extraction)하고 분류(classifier)를 수행한다.
- GPU를 사용할 수 있다면 모델을 GPU로 이동한다.
- 손실 함수와 옵티마이저 설정
- 분류 문제에 적합한 CrossEntropyLoss를 손실 함수로 사용한다.
- SGD 옵티마이저로 모델 파라미터를 학습시킨다.
- 모델 학습
- 학습 데이터를 반복적으로 모델에 입력하고 손실을 계산한 뒤 역전파와 가중치 업데이트를 수행한다.
- 각 에포크마다 평균 손실을 기록한다.
- 결과 시각화
- 학습 중 손실 값의 변화를 그래프로 시각화하여 학습 과정을 확인한다.
- 모델 평가
- 테스트 데이터셋을 사용해 모델의 예측 성능을 평가한다.
- 예측값과 실제값을 비교해 분류 정확도를 계산한다.
이제 코드를 뜯어보자.
데이터 전처리 및 로드
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)transform은 데이터 전처리를 정의하는 부분이다.
이미지 데이터는 원래 픽셀 값이 0에서 255 사이의 정수로 표현되기 때문에
딥러닝 모델의 입력으로 직접 사용하면 학습이 어려워진다.
ToTensor()와 Normalize()를 통해 데이터의 범위를 조정하고 분포를 표준화함으로써 모델이 더 잘 학습할 수 있도록 한다.
이러한 전처리는 학습 성능과 안정성을 높이는 데 필수적이다.
ToTensor()
ToTensor()는 이미지 데이터를 PyTorch 텐서(tensor)로 변환한다.
텐서는 다차원 배열 형태로 데이터를 표현하며, 딥러닝 모델의 입력으로 사용된다.
ToTensor()가 적용되면 이미지의 픽셀 값이 다음과 같이 변환된다:
- 원래 이미지는 0에서 255 사이의 값으로 표현된다(정수 값).
- ToTensor()는 각 픽셀 값을 0.0에서 1.0 사이로 정규화된 실수 값으로 변환한다. 이는 픽셀 값을 255로 나누는 과정을 통해 이루어진다.
예를 들어, 픽셀 값이 128인 경우 128 / 255 = 0.50196으로 변환된다.
이렇게 하면 신경망이 계산하기 쉬운 범위로 데이터가 조정된다.
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
Normalize(mean, std)는 각 채널(RGB)에 대해 평균(mean)과 표준편차(std)를 사용해 정규화한다.
CIFAR-10은 RGB 채널로 구성된 컬러 이미지로, 각 채널의 값을 별도로 정규화한다.
정규화 공식은 다음과 같다:
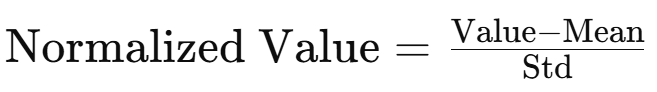
- 평균(mean): (0.5, 0.5, 0.5)
각 채널(R, G, B)의 평균값을 0.5로 설정한다.
이는 데이터 분포를 중심(0)으로 맞추는 역할을 한다. - 표준편차(std): (0.5, 0.5, 0.5)
각 채널의 표준편차 값을 0.5로 설정한다.
이는 값의 분포를 -1에서 1 사이로 축소한다.
예를 들어, 정규화 전에 픽셀 값이 0.50196이었다면 정규화 후에는 다음과 같다:
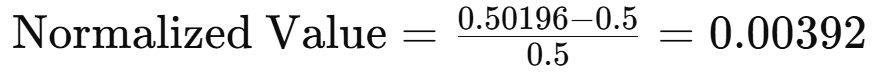
왜 정규화를 하는가?
- 학습 안정성
신경망은 입력 데이터가 평균 0, 분산 1에 가까운 분포일 때 더 안정적으로 학습한다.
이를 통해 모델이 더 빠르게 수렴하고, 학습 속도를 개선할 수 있다. - 스케일 통일
데이터의 값이 일정한 범위(-1에서 1) 내에 존재하면, 특정 입력 값이 지나치게 크거나 작아지는 것을 방지한다.
이는 각 입력 값이 모델의 가중치 업데이트에 균등하게 영향을 미치도록 한다. - 채널 간 균형 유지
RGB 채널의 평균과 분산을 맞춤으로써 각 채널이 균등하게 학습에 기여하도록 한다.
만약 특정 채널의 값이 너무 크거나 작다면, 모델이 해당 채널에만 의존하게 되는 현상이 발생할 수 있다.
CNN 모델 정의
CNN(Convolutional Neural Network)
CNN(Convolutional Neural Network)은 이미지 데이터를 다루는 데 매우 적합한 신경망이다.
이미지는 픽셀로 이루어진 2차원 데이터이기 때문에,
기존의 완전 연결 신경망(Fully Connected Neural Network) 보다 공간적 구조를 유지하면서 처리하는 CNN이 더 효율적이다.
CNN은 합성곱(convolution) 연산을 통해 이미지의 패턴(예: 윤곽선, 색상 변화)을 추출하며,
풀링(pooling) 연산으로 데이터를 축소해 연산량을 줄이고 불필요한 정보를 제거한다.
합성곱 신경망(Convolutional Neural Network, CNN)
합성곱 신경망(Convolutional Neural Network, CNN)
목차 딥러닝의 역사와 발전: 머신러닝에서 딥러닝까지의 여정 인공 신경망의 기본 구조와 중요성 활성화 함수(Activation Functions) 이해하기 손실 함수(Loss Functions)의 역할과 중요성 딥러닝에서의
gnidinger.tistory.com
코드 분석
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(3, 6, 5), nn.ReLU(), nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5), nn.ReLU(), nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120), nn.ReLU(), nn.Linear(120, 10)
)
def forward(self, x):
x = self.feature_extraction(x)
x = x.view(-1, 16 * 5 * 5)
x = self.classifier(x)
return x
feature_extraction (특징 추출)
이 부분은 이미지의 중요한 특징을 추출하는 역할을 한다. 이미지를 작은 단위로 분석하며 점차 높은 수준의 정보를 생성해 나간다.
- nn.Conv2d(3, 6, 5)
- 입력 채널(3): 입력 이미지가 RGB 컬러이므로 채널 수는 3이다.
- 출력 채널(6): 6개의 필터를 사용해 입력 이미지를 변환한다. 각 필터는 이미지의 특징을 추출한다. 필터는 작은 패턴(예: 모서리, 점)부터 시작해 더 복잡한 패턴까지 학습한다.
- 필터 크기(5x5): 5x5 크기의 필터를 사용해 입력 이미지의 작은 부분을 살펴본다. 이는 지역적 정보를 캡처하는 역할을 한다.
- nn.ReLU()
활성화 함수로, 입력 값이 0보다 작으면 0으로, 0 이상이면 그대로 반환한다.
비선형성을 추가해 신경망이 복잡한 문제를 해결할 수 있도록 돕는다. - nn.MaxPool2d(2, 2)
2x2 크기의 풀링 연산을 수행하며, 해당 영역에서 가장 큰 값을 선택한다.
특징 맵 크기를 절반으로 줄여 계산 효율을 높이고, 중요한 정보를 유지한다.
classifier (분류기)
이 부분은 CNN이 추출한 특징을 이용해 이미지를 분류하는 역할을 한다.
- nn.Linear(16 * 5 * 5, 120)
- 입력(16 * 5 * 5): 특징 추출 단계에서 나온 결과를 평탄화(flatten) 한 것이다. 16개의 채널에 각각 5x5 크기의 특징 맵이 있으므로 총 400개의 값이 입력된다.
- 출력(120): 중간 계층의 뉴런 수이다. 이 수는 모델 설계자가 설정하며, 학습 과정에서 조정할 수 있다.
- nn.Linear(120, 10)
출력 뉴런 수는 CIFAR-10 데이터셋의 클래스 수(10개)와 같다. 각 출력 뉴런은 특정 클래스에 대한 점수를 나타낸다.
forward 메서드
forward(x)는 모델의 순전파(forward pass)를 정의한다. 입력 이미지를 네트워크에 통과시키고, 최종 결과를 반환한다.
- feature_extraction 실행
- 입력 이미지를 합성곱과 풀링 연산을 통해 특징 맵으로 변환한다.
- 특징 맵은 차원이 줄어들고, 중요한 정보가 추출된다.
- x.view(-1, 16 * 5 * 5)
- CNN의 출력인 2차원 데이터를 평탄화하여 1차원 벡터로 변환한다.
- 신경망의 분류기 부분(classifier)에서 사용할 수 있는 형태로 만든다.
- classifier 실행
- 평탄화된 데이터를 선형 계층(nn.Linear)에 전달해 최종 분류 점수를 계산한다.
- 각 클래스에 대한 점수를 반환한다.
CNN 모델 구조 요약
- 특징 추출(feature_extraction): 이미지에서 유용한 정보를 추출한다.
- 평탄화: CNN의 2차원 출력 데이터를 1차원으로 변환한다.
- 분류(classifier): 추출된 특징을 기반으로 클래스별 점수를 계산한다.
이 과정은 이미지 분류 문제를 해결하는 데 적합하며, CIFAR-10 데이터셋처럼 작은 이미지에도 효과적이다.
모델 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = CNN().to(device)
torch.device
torch.device는 텐서와 모델이 실행될 장치를 지정한다.
- cuda:0: 첫 번째 GPU를 나타낸다. cuda가 사용 가능하면 이 장치를 사용한다.
- cpu: GPU가 없거나 CUDA를 사용할 수 없는 경우 기본적으로 CPU를 사용한다.
torch.cuda.is_available()는 CUDA 지원 여부를 확인하는 함수이다.
- CUDA는 NVIDIA에서 제공하는 GPU 가속 라이브러리이다. 딥러닝에서 계산 속도를 대폭 향상한다.
- 이 함수가 True를 반환하면 GPU를 사용할 수 있다는 뜻이다.
위 코드는 GPU가 사용 가능한 환경이라면 cuda:0을, 그렇지 않다면 cpu를 device로 설정한다.
to(device)
net = CNN()은 CNN 모델을 생성한다.
- 생성된 모델은 기본적으로 CPU에 할당된다. GPU를 사용하려면 모델을 명시적으로 GPU로 이동시켜야 한다.
- .to(device)는 모델이 실행될 장치를 지정한다. 여기서는 device에 저장된 값에 따라 GPU나 CPU로 모델을 이동시킨다.
모델이 GPU로 이동하면 계산은 GPU에서 수행되고, CPU로 이동하면 CPU에서 수행된다.
GPU 사용의 장점
GPU는 병렬 계산에 특화되어 있다.
딥러닝에서는 수많은 행렬 곱셈 및 합성곱 연산이 이루어지는데, GPU는 이를 병렬로 처리하여 학습 속도를 크게 높인다.
CPU는 보통 직렬 연산에 강점이 있어 학습 속도가 상대적으로 느리다.
특히 이미지 데이터처럼 계산량이 많은 경우, GPU를 활용하면 효율적으로 학습을 진행할 수 있다.
요약
- torch.device로 실행 장치를 설정한다.
- CNN()으로 CNN 모델을 생성한다.
- .to(device)를 사용하여 모델을 설정한 장치로 이동시킨다.
- GPU가 사용 가능하면 GPU로 이동한다.
- 그렇지 않으면 CPU에서 실행된다.
손실 함수와 옵티마이저
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
손실 함수: nn.CrossEntropyLoss
- nn.CrossEntropyLoss는 분류(classification) 문제에 적합한 손실 함수이다.
- 이 함수는 모델의 예측값과 실제 라벨 간의 차이를 계산하며, 이를 줄이는 방향으로 모델이 학습한다.
- 예측값(outputs)은 모델의 마지막 레이어에서 계산된 로짓(logit)이다.
로짓은 확률 값으로 변환되기 전의 실수 값이며, 일반적으로 정규화되지 않은 상태이다. - nn.CrossEntropyLoss는 내부적으로 소프트맥스(softmax) 연산을 포함하고 있다.
소프트맥스는 로짓을 확률로 변환하는 함수로, 예측값의 합이 1이 되도록 정규화한다.
왜 소프트맥스 활성화 함수가 포함되어 있을까?
- 일반적으로 다중 클래스 분류 문제에서는 각 클래스의 확률 값을 계산해야 한다.
이를 위해 소프트맥스를 적용해 확률로 변환한다. - nn.CrossEntropyLoss는 이 과정을 손실 함수 내부에서 처리한다.
따라서 모델의 출력 레이어에 소프트맥스를 추가로 적용할 필요가 없다.
옵티마이저: optim.SGD
- optim.SGD는 경사 하강법(Gradient Descent)의 변형인 확률적 경사 하강법(Stochastic Gradient Descent)을 구현한다.
- 경사 하강법(Gradient Descent)은 손실 함수의 기울기를 계산해 가중치(weight)를 업데이트하는 알고리즘이다.
- 손실 함숫값이 최소화되는 방향으로 모델의 가중치를 조정한다.
- 확률적(Stochastic)이란 용어는 매번 전체 데이터를 사용하지 않고, 미니배치(mini-batch) 데이터를 사용해 업데이트를 진행한다는 것을 의미한다.
- 이를 통해 계산 속도를 높이고 메모리 사용량을 줄일 수 있다.
- lr (Learning Rate, 학습률)
- 학습률은 모델이 기울기를 따라 이동하는 크기를 결정한다.
- 값이 너무 크면 최적의 값을 지나칠 위험이 있고, 값이 너무 작으면 학습이 느려진다.
- momentum
- 모멘텀은 이전 업데이트 값을 일정 부분 반영해 현재 업데이트에 가속도를 더한다.
- 이를 통해 지역 최솟값(local minima)에서 벗어나고, 최적화 속도를 높일 수 있다.
손실 함수와 옵티마이저의 상호작용
- 모델의 출력(outputs)과 실제 라벨(labels)을 nn.CrossEntropyLoss에 전달해 손실값을 계산한다.
- 이 손실값을 바탕으로 optim.SGD가 가중치를 업데이트한다.
- 손실 함수와 옵티마이저는 딥러닝 모델 학습의 핵심 구성 요소이다.
손실 함수는 모델이 얼마나 틀렸는지를 알려주며, 옵티마이저는 이 틀림을 줄이기 위해 모델을 개선한다.
모델 학습
for epoch in pbar:
running_loss = 0.0
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_.append(running_loss / n)학습 데이터에 대해 여러 에포크(epoch) 동안 모델을 반복적으로 학습시키며
예측(outputs) → 손실 계산(loss) → 역전파(backward()) → 가중치 업데이트(step())를 수행한다.
외부 루프: 에포크(epoch)
for epoch in pbar:- epoch는 학습 데이터 전체를 한 번 학습하는 주기이다.
- 외부 루프는 학습 데이터 전체를 반복하는 에포크 수를 제어한다.
- pbar는 진행 상황을 시각적으로 표시하는 객체이다. 학습의 현재 상태를 확인할 수 있게 한다.
내부 루프: 배치(batch) 처리
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device)- trainloader는 학습 데이터를 배치 단위로 제공한다.
- data[0]는 입력 이미지, data[1]는 해당 이미지의 실제 클래스(label)이다.
- .to(device)를 호출하여 데이터를 CPU 또는 GPU로 이동시킨다. 이렇게 하면 모델과 데이터가 동일한 장치에서 처리된다.
그레이디언트 초기화
optimizer.zero_grad()- 이전 배치에서 계산된 그레이디언트 값을 초기화한다.
- PyTorch는 그레이디언트를 누적 방식으로 계산하기 때문에, 초기화하지 않으면 이전 배치의 값이 누적되어 학습이 잘못될 수 있다.
예측 값 계산
outputs = net(inputs)- 모델(net)에 입력 데이터를 전달하여 예측값(outputs)을 계산한다.
- 예측값은 CIFAR-10의 각 클래스(총 10개)에 대한 점수를 포함한다.
손실 계산
loss = criterion(outputs, labels)- 손실 함수(criterion)를 사용하여 모델의 예측값(outputs)과 실제값(labels) 간의 차이를 계산한다.
- 여기서 사용된 손실 함수는 교차 엔트로피 손실(CrossEntropyLoss)이다.
이 함수는 예측 확률 분포와 실제 클래스 간의 차이를 측정한다.
역전파 수행
loss.backward()- loss.backward()는 손실 값에 대한 모델 파라미터의 그레이디언트를 계산한다.
- 역전파(backpropagation)를 통해 각 파라미터가 얼마나 조정되어야 하는지 알 수 있다.
가중치 업데이트
optimizer.step()- 옵티마이저(optimizer)가 계산된 그레이디언트를 사용하여 모델의 가중치를 업데이트한다.
- 여기서는 **확률적 경사 하강법(SGD)**이 사용되며, 학습률(lr)과 모멘텀(momentum)이 적용된다.
손실 누적
running_loss += loss.item()- 현재 배치의 손실 값을 running_loss에 더한다.
- loss.item()은 손실 값을 파이썬 숫자로 변환하여 누적할 수 있게 한다.
에포크 평균 손실 계산
l = running_loss / n
loss_.append(l)- n은 배치의 개수이다. 이를 이용해 에포크 동안 발생한 손실의 평균을 계산한다.
- 계산된 평균 손실(l)을 리스트(loss_)에 저장하여 이후에 그래프로 시각화할 수 있다.
데이터 흐름 요약
- 입력 데이터를 배치 단위로 가져온다.
- 모델에 입력 데이터를 전달하여 예측값을 계산한다.
- 손실 함수를 사용해 예측값과 실제 값 간의 차이를 계산한다.
- 역전파를 통해 모델의 가중치를 조정한다.
- 에포크가 끝날 때, 평균 손실 값을 기록한다.
이 과정을 반복하면서 모델이 점점 더 데이터에 적합하도록 학습된다.
테스트 데이터로 모델 평가
correct = 0
total = 0
with torch.no_grad():
net.eval()
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy of the network on the 10000 test images: %d %%" % (100 * correct / total))
코드 시작
correct = 0
total = 0- correct: 모델이 정확히 맞춘 샘플의 수를 저장한다.
- total: 전체 테스트 샘플 수를 저장한다.
테스트 데이터를 평가하며, 맞춘 샘플 수와 총 샘플 수를 사용해 정확도를 계산한다.
torch.no_grad()
with torch.no_grad():- 역전파 계산 비활성화:
테스트 시에는 모델의 가중치를 업데이트하지 않는다. torch.no_grad()는 이 과정에서의 그래프 생성과 메모리 사용을 막아 속도와 효율을 높인다. - 메모리 최적화:
그래프를 생성하지 않기 때문에 메모리 사용량이 줄어든다. 이는 테스트와 추론 단계에서 유용하다.
net.eval()
net.eval()- 평가 모드 전환:
모델을 평가 모드로 설정한다. 학습 모드와 달리 드롭아웃(Dropout)과 배치 정규화(Batch Normalization)와 같은 학습 전용 연산이 비활성화된다. - 필요성:
테스트 단계에서는 입력 데이터만 가지고 모델의 성능을 평가하므로 학습 전용 연산이 필요하지 않다.
테스트 데이터 순회
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)- testloader:
테스트 데이터셋에서 배치 단위로 데이터를 불러온다. - images와 labels:
- images: 테스트 이미지 데이터로 입력된다.
- labels: 각 이미지의 실제 클래스(정답)이다.
- to(device):
데이터를 GPU 또는 CPU로 옮긴다.
모델 출력값 계산
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)- outputs:
모델이 예측한 클래스별 점수(logit)이다. 크기는 [배치 크기, 클래스 수]가 된다. - torch.max(outputs.data, 1):
클래스별 점수 중 가장 큰 값을 가진 클래스의 인덱스를 반환한다.
- outputs.data: 모델 출력 값에서 계산 그래프를 제외한 텐서를 사용한다.
- 1: 행 단위로(배치별로) 최댓값을 찾는다.
- predicted:
각 이미지에 대해 모델이 예측한 클래스의 인덱스이다.
_
_는 파이썬에서 변수 이름을 생략할 때 사용하는 관례적인 이름이다.
이 코드에서는 torch.max 함수가 반환하는 값 중 필요하지 않은 값을 무시하는 역할을 한다.
torch.max 함수의 반환값은 (max_values, indices)의 튜플인데, 여기서 최댓값은 무시하고 그 인덱스만 가져오겠다는 뜻이다.
정확도 계산
total += labels.size(0)
correct += (predicted == labels).sum().item()- total:
배치 내 모든 이미지의 개수를 누적한다. labels.size(0)는 현재 배치의 이미지 개수이다. - correct:
모델이 정확히 예측한 이미지의 개수를 누적한다.
- predicted == labels: 모델의 예측값과 실제값이 일치하면 True, 일치하지 않으면 False를 반환한다.
- .sum().item(): True 값을 합산하여 정수로 반환한다.
결과 출력
print("Accuracy of the network on the 10000 test images: %d %%" % (100 * correct / total))- 정확도 계산:
(100 * correct / total)로 모델이 정확히 예측한 비율(정확도)을 백분율로 계산한다. - 출력 결과:
"Accuracy of the network on the 10000 test images: XX %" 형식으로 테스트 정확도를 출력한다.
평가 프로세스 요약
- 테스트 데이터를 배치 단위로 순회한다.
- 모델이 각 배치에 대해 예측한 클래스를 계산한다.
- 예측값과 실제값을 비교하여 맞춘 개수를 누적한다.
- 총 맞춘 개수를 전체 데이터 개수로 나누어 정확도를 계산한다.
정리
이렇게 해서 기초적인 CNN모델과 CIFAR-10 데이터셋을 이용한 모델 학습 코드를 뜯어보았다.
실제 개발이나 연구 과정에서는 가중치 행렬과 활성화 함수, 손실함수, 최적화 함수, 거기에 신경망 깊이까지 바꿔가며
테스트하고 수정하고 해야 한다는 생각에 다소 까마득하다는 생각이 들었다.
긍정적인 면은 지난 글을 쓰고 이번 글을 적으니 단어와 로직에 익숙해진다는 점.
계속 정리하며 가보자.
끝!
'Python > PyTorch' 카테고리의 다른 글
| [Pytorch]Vanilla RNN과 확장된 기법들: LSTM, GRU, Bidirectional LSTM, Transformer (2) | 2024.12.03 |
|---|---|
| [PyTorch]전이 학습(Transfer Learning) (0) | 2024.11.27 |
| [PyTorch]Vanilla RNN을 활용한 코스피 예측 문제 (1) | 2024.11.26 |
| [PyTorch]MLP를 활용한 회귀 문제 해결 방법(집값 예측) (2) | 2024.11.22 |
| [PyTorch]PyTorch 환경설정 및 MNIST 실습 (0) | 2023.08.30 |
| [PyTorch]갑자기 써보는, PyTorch에 대하여 (1) | 2023.08.26 |
- Total
- Today
- Yesterday
- 알고리즘
- 세계일주
- 야경
- Algorithm
- RX100M5
- 중남미
- 리스트
- 기술면접
- 세계여행
- Backjoon
- spring
- 남미
- 스프링
- 칼이사
- 백준
- 스트림
- 면접 준비
- 맛집
- 유럽여행
- 자바
- a6000
- 파이썬
- 여행
- 세모
- 지지
- Python
- BOJ
- java
- 동적계획법
- 유럽
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |