

티스토리 뷰
[선형대수학]주성분 분석(Principal Component Analysis, PCA)
Vagabund.Gni 2024. 2. 22. 23:00목차
[선형대수학]머신러닝과 딥 러닝의 핵심, 선형대수학의 역할과 중요성
[선형대수학]부분행렬과 분할행렬: 공통점과 차이점, ML/DL에의 응용
[선형대수학]역행렬과 행렬식의 성질, ML/DL과의 관계
[선형대수학]행렬의 해와 감소된 행 계단형(Reduced Row Echelon Form, RREF)
[선형대수학]벡터 공간과 기저, 차원 그리고 ML/DL
[선형대수학]선형변환과 고윳값의 이해: 머신러닝/딥러닝에서의 응용
[선형대수학]벡터 공간의 대각화와 그 응용 - 유사 행렬 및 머신러닝에서의 중요성
[선형대수학]특이값 분해(SVD): 기본부터 머신러닝/딥러닝까지의 응용
[선형대수학]실 이차 형식과 양의 정부호 행렬: 머신러닝/딥러닝에의 응용
Introduction
주성분 분석(Principal Component Analysis, PCA)은 고차원 데이터를 분석하고 이해하기 위한 강력한 통계적 방법이다.
이 방법은 데이터의 차원을 축소하여 핵심적인 정보를 보존하는 데 중점을 둔다.
본 게시글에서는 PCA의 정의와 성질 및 연산 과정, 분산과 공분산 행렬의 개념, Elbow Point에 대해 쉽고 상세하게 설명한다.
Principal Component Analysis, PCA


주성분 분석은 데이터의 가장 중요한 정보를 포함하는 새로운 변수,
즉 '주성분(principal components)'을 찾아내는 기법이다.
이 과정에서 원본 데이터의 차원을 줄이는 차원 축소가 이루어진다.
PCA의 목표는 데이터가 투사되는 새로운 축(주성분)을 찾는 것이며,
이 축들은 원본 데이터의 분산을 최대화하는 방향을 가리킨다.
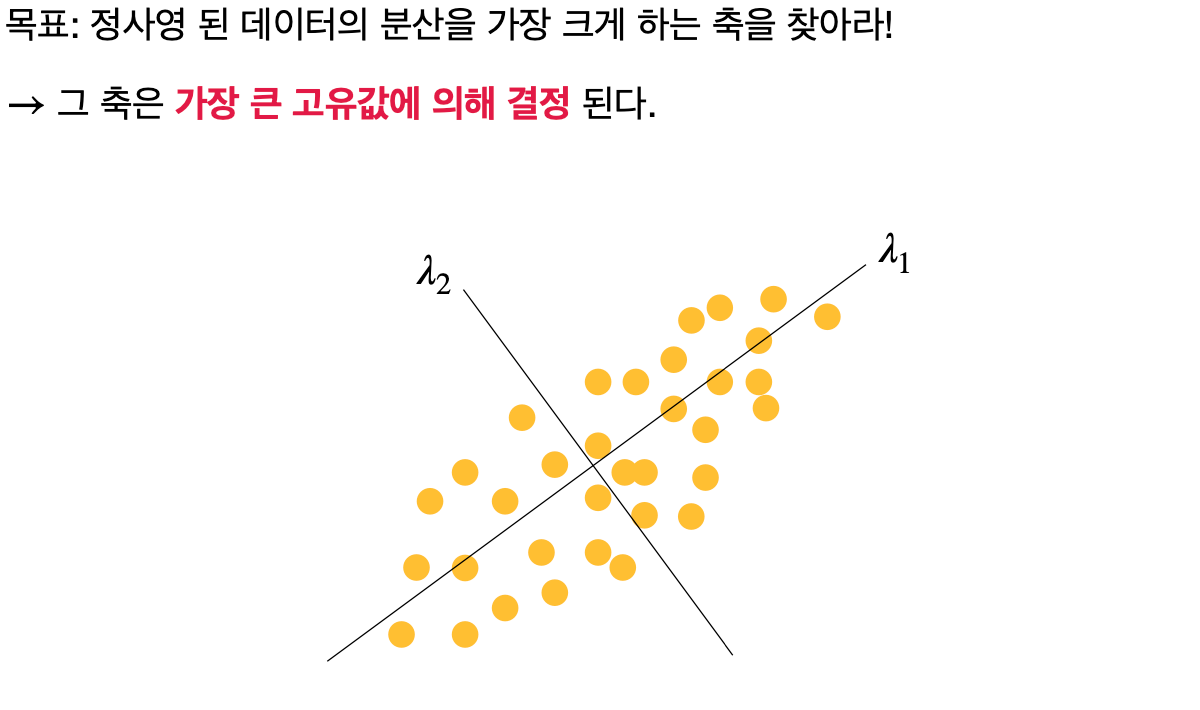
주성분은 데이터의 공분산 행렬을 기반으로 계산되며,
가장 큰 고윳값(eigenvalue)을 가지는 고유벡터(eigenvector)가 첫 번째 주성분이 된다.
Variance and Covariance Matrix
Variance
분산은 데이터가 평균에서 얼마나 멀리 떨어져 있는지를 측정하는 값이다.
즉, 분산은 데이터의 흩어진 정도를 나타낸다.
수학적으로, 분산은 데이터 포인트가 평균으로부터 얼마나 떨어져 있는지의 제곱의 평균으로 계산된다.
분산이 크다는 것은 데이터 포인트들이 평균으로부터 넓게 퍼져 있다는 것을 의미하며,
분산이 작다는 것은 데이터 포인트들이 평균 근처에 밀집해 있다는 것을 의미한다.
Covariance Matrix
공분산은 두 변수 간의 상호 변동성을 측정한다.
이는 두 변수가 어떻게 함께 변하는지를 나타내며, 이를 통해 변수 간의 선형 관계의 강도와 방향을 파악할 수 있다.
공분산이 양수면 두 변수가 같은 방향으로 변동하고, 공분산이 음수면 두 변수가 반대 방향으로 변동한다.
공분산 행렬은 데이터 세트의 모든 변수 쌍에 대한 공분산 값을 포함하는 정사각 행렬이다.
이 행렬은 다변량 데이터의 상관 구조를 나타내며, 주성분 분석에서 매우 중요한 역할을 한다.
공분산 행렬을 통해, 데이터 세트의 주요 변동 방향을 찾아내고,
이 방향들이 데이터의 가장 중요한 특성을 나타내는 축(주성분)이 된다.
공분산 행렬은 다음과 같이 계산된다:
- 각 변수에 대한 평균을 계산한다.
- 각 변수 쌍에 대해, 한 변수의 값이 그 평균에서 얼마나 떨어져 있는지와
다른 변수의 값이 그 평균에서 얼마나 떨어져 있는지의 곱의 평균을 계산한다. 이 값이 공분산이다. - 모든 변수 쌍에 대해 이 과정을 반복하고, 결과를 행렬 형태로 정리한다.
이렇게 구성된 공분산 행렬은 PCA를 수행함으로써 데이터의 주요 특성과 패턴을 추출하는 데 사용된다.
공분산 행렬의 고윳값과 고유벡터를 분석함으로써 데이터 세트 내에서 가장 중요한 변동 방향을 찾아낼 수 있으며,
이는 데이터의 차원을 축소하고, 본질적인 정보를 보존하는 데 핵심적인 역할을 한다.
Steps in PCA

PCA는 다음과 같은 순서로 진행된다:
- 데이터 표준화
주성분 분석을 시작하기 전에, 모든 변수의 평균을 0으로, 표준편차를 1로 맞추기 위해 데이터를 표준화한다.
이는 모든 변수가 분석에 동등하게 기여하도록 하는 중요한 단계이다. - 공분산 행렬 계산
데이터의 공분산 행렬을 계산한다.
이 행렬은 변수 간의 상호 변동성을 캡처하며, 데이터가 어떻게 함께 변하는지를 나타낸다.
공분산 행렬의 각 요소는 두 변수 간의 공분산을 나타내며, 대각선 요소는 각 변수의 분산을 나타낸다. - 고윳값과 고유벡터 계산
공분산 행렬의 고윳값과 고유벡터를 계산한다.
고유벡터는 데이터가 투영될 새로운 축(주성분)을 나타내며, 고윳값은 그 축의 중요도(변수의 분산)를 나타낸다.
고유벡터는 서로 직교(orthonormal)한다. - 주성분 선정
고윳값을 크기 순으로 나열하고, 가장 큰 고윳값을 가진 고유벡터부터 차례대로 주성분으로 선정한다.
첫 번째 주성분은 데이터의 가장 큰 분산 방향을 나타내고,
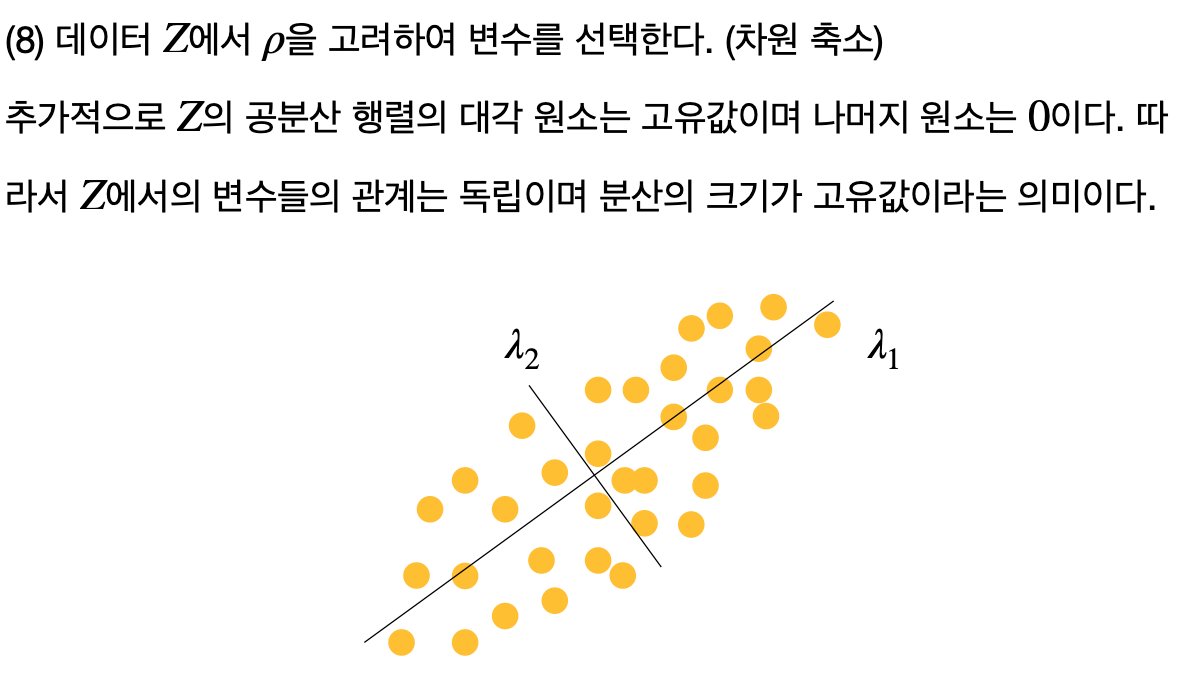
두 번째 주성분은 첫 번째 주성분과 직교하는 방향 중 가장 큰 분산을 나타내는 축을 의미한다. - 새로운 데이터 차원 구성
선택된 주성분을 기반으로 새로운 차원을 구성한다.
이는 원본 데이터를 주성분 축에 투영하여 얻어지며, 차원 축소가 이루어지는 단계이다.
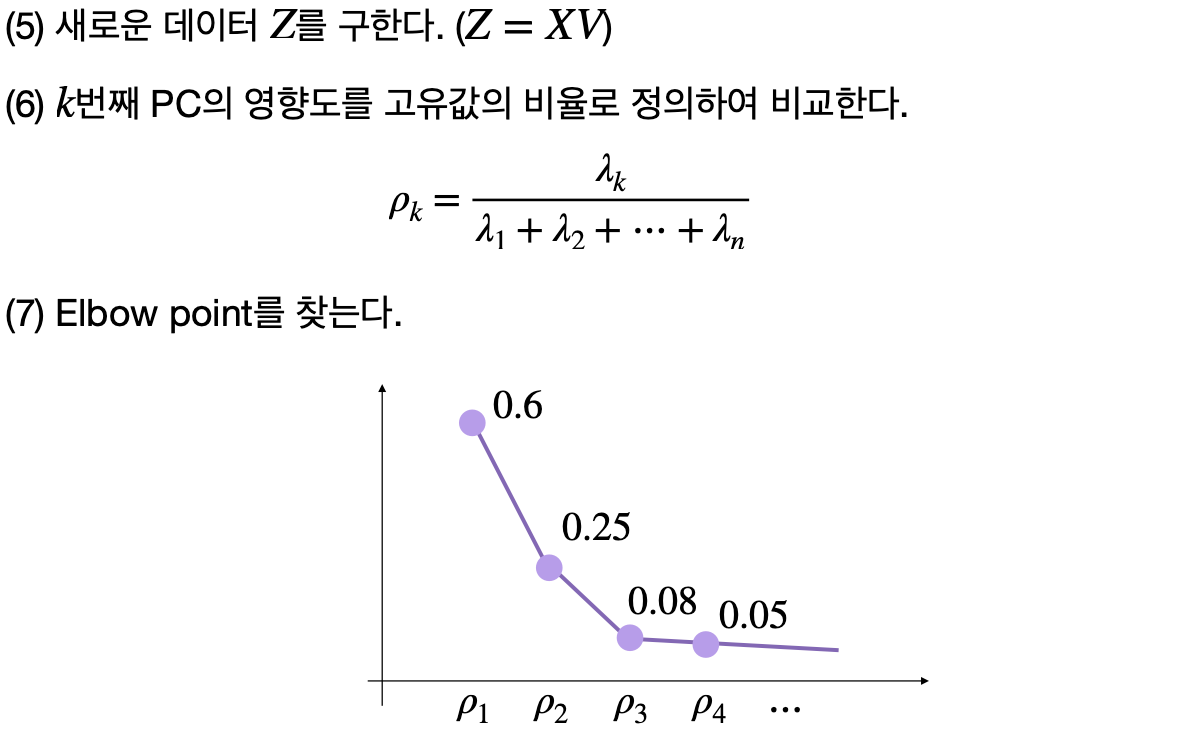
데이터 포인트는 이제 더 낮은 차원에서 표현된다. - 주성분의 영향도 비교
각 주성분의 영향도를 고윳값의 비율로 정의하여 비교한다.
이 비율은 전체 분산 중 해당 주성분이 차지하는 비중을 나타내며, 중요도에 따라 주성분을 선택하는 기준이 된다. - Elbow Point 찾기
고윳값의 크기를 나열한 그래프에서, 고윳값의 감소가 급격히 줄어드는 지점, 즉 'Elbow Point'를 찾는다.
이 지점 이후의 주성분은 상대적으로 중요도가 낮다고 판단하여, 차원 축소 시 고려하지 않는다. - 차원 축소
선택된 주성분만을 유지하고, 나머지는 제거하여 데이터의 차원을 축소한다.
이는 데이터를 더욱 간결하게 표현하며, 계산 비용을 줄이고, 시각화를 용이하게 한다.
Conclusion
주성분 분석은 데이터의 핵심적인 특성을 추출하고 이해하는 데 매우 유용한 도구이다.
선형대수학의 개념을 활용하여 데이터의 구조를 분석하는 이 방법은,
복잡한 데이터 세트에서 중요한 정보를 시각화하고 해석하는 데 있어 필수적이다.
본 게시글이 주성분 분석의 개념과 중요성을 이해하는 데 도움이 되길 바란다.
'ML+DL > Linear Algebra' 카테고리의 다른 글
| [선형대수학]Factorization Machines (0) | 2024.02.23 |
|---|---|
| [선형대수학]실 이차 형식과 양의 정부호 행렬: 머신러닝/딥러닝에의 응용 (0) | 2024.02.21 |
| [선형대수학]특이값 분해와 고윳값: 공통점과 차이점 (0) | 2024.02.21 |
| [선형대수학]특이값 분해(SVD): 기본부터 머신러닝/딥러닝까지의 응용 (0) | 2024.02.21 |
| [선형대수학]벡터 공간의 대각화와 그 응용 - 유사 행렬 및 머신러닝에서의 중요성 (0) | 2024.02.20 |
| [선형대수학]선형변환과 고윳값의 이해: 머신러닝/딥러닝에서의 응용 (0) | 2024.02.19 |
- Total
- Today
- Yesterday
- 여행
- 면접 준비
- 야경
- 기술면접
- 스트림
- 백준
- 세계일주
- RX100M5
- 지지
- 자바
- a6000
- 동적계획법
- 알고리즘
- 칼이사
- 유럽
- Python
- 리스트
- 세모
- Backjoon
- spring
- 맛집
- Algorithm
- BOJ
- 남미
- 유럽여행
- 스프링
- 중남미
- 파이썬
- java
- 세계여행
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |