

티스토리 뷰
목차
활성화 함수(Activation Functions) 이해하기
손실 함수(Loss Functions)의 역할과 중요성
확률적 경사 하강법(Stochastic Gradient Descent, SGD)
합성곱 신경망(Convolutional Neural Network, CNN)
순환 신경망(Recurrent Neural Network, RNN)
순환 신경망의 발전(The Evolution of RNN)
Introduction
세상을 바라보는 우리 눈은 빛의 퍼즐을 조각조각 맞추어 완성된 그림을 본다.
컴퓨터도 마찬가지로 이미지를 수많은 픽셀의 집합으로 보고, 그 속에 숨은 의미를 찾아내려 애쓴다.
이 글에서는 이러한 과정을 가능하게 하는 딥러닝의 핵심 기술인 합성곱 연산에 대해 간단히 알아보려 한다.
Image Data
현대의 딥러닝은 이미지 데이터를 핵심으로 다룬다.
이미지는 픽셀로 구성되어 있으며, 각 픽셀은 색상을 나타내는 값들을 갖는다.

컬러 이미지의 경우 RGB 채널이 각각 존재하여, 500x250 크기의 이미지는 사실상 500x250x3의 데이터 크기를 가진다.
이런 고차원 데이터를 효과적으로 처리하는 것이 중요하다.
Image Preprocessing

이미지를 딥러닝 모델에 입력하기 전에는 여러 전처리 과정을 거친다.
목적에 따라 크기 조정, 색상 변경, 잡음 제거 등이 이루어지며,
이는 모델이 학습하기 쉬운 형태로 데이터를 조정하는 데 도움을 준다.
MLP with Image Data
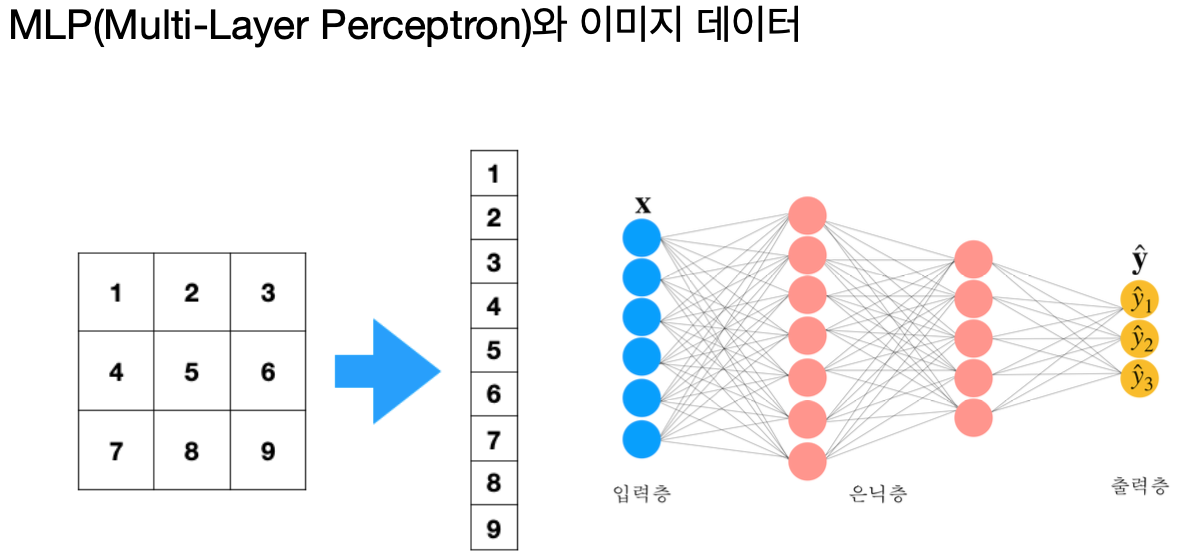
다층 퍼셉트론(MLP)은 기본적인 딥러닝 모델로,
각 뉴런이 데이터의 모든 특성과 연결되어 있어 복잡한 패턴을 인식하는 데 유용하다고 여겨졌다.
하지만 이미지 데이터를 이해한다는 것은 단순히 픽셀 값의 조합을 넘어,
그림 속에 내재된 구조와 객체의 형태를 파악하는 것을 포함한다.

MLP는 이미지의 지역적 특성, 즉 가까이 있는 픽셀 간의 관계가 전체 패턴 인식에 중요하다는 점을 반영하지 못한다.
또한, 이미지가 커질수록 파라미터의 수가 기하급수적으로 증가하여 계산 비용이 매우 높아지고,
이로 인해 과적합(overfitting)이 발생하기 쉬워진다.
즉, MLP는 픽셀 간의 국소적 패턴을 효과적으로 학습하는 데 제한적이며,
이미지의 전반적인 구조적 특성을 이해하는 데 한계를 보인다.
Introduction of CNN
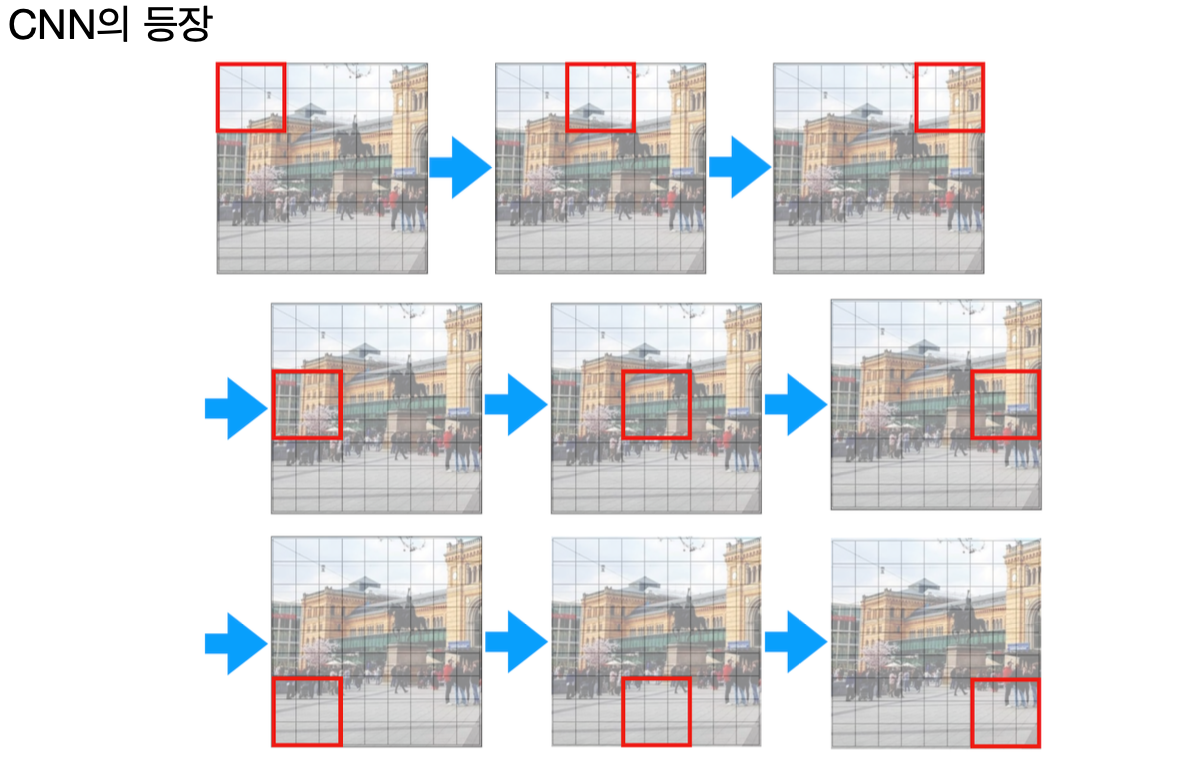
합성곱 신경망(CNN)은 MLP의 한계를 극복하기 위해 등장했다.
CNN은 이미지의 지역적인 패턴을 잘 인식할 수 있는 구조로, 특히 시각적 패턴을 인식하는 데 강력한 성능을 발휘한다.
이전의 MLP가 전체 이미지를 단순한 숫자의 배열로만 바라보며 각 픽셀 간 복잡한 관계를 놓쳤다면,
CNN은 이미지를 구성하는 패턴과 구조를 지능적으로 포착한다.
그 비밀은 바로 '합성곱 연산'에 있다.
이 연산을 통해 CNN은 이미지를 다양한 각도와 크기에서의 형태, 색채의 변화,
그림자의 미묘함까지도 인식할 수 있는 능력을 갖추게 되었다.
합성곱 층이라는 특별한 레이어가 국소적인 정보를 추출하며, 이를 쌓아 올려 가며 복잡한 형태와 객체를 학습한다.
각 층은 점점 더 높은 수준의 특징들을 포착해 나가며,
이러한 계층적인 구조는 결국 이미지를 이해하는 강력한 시스템을 만들어낸다.
계속해서 합성곱 연산에서 사용되는 단어를 몇 개 공부하고 지나가자.
Filter
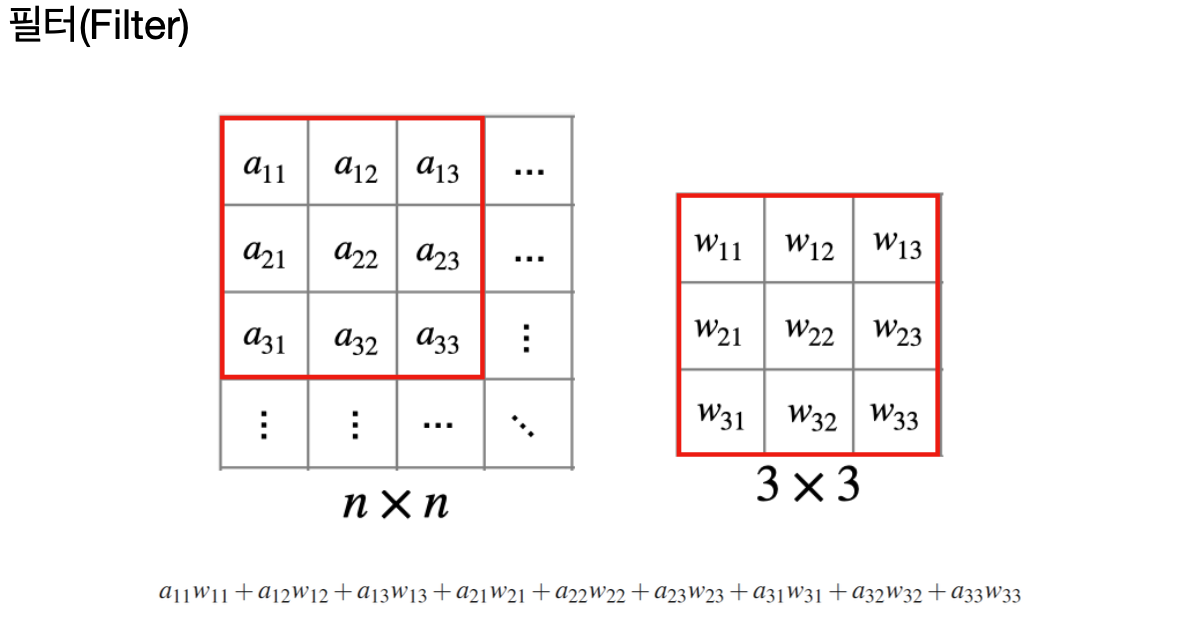
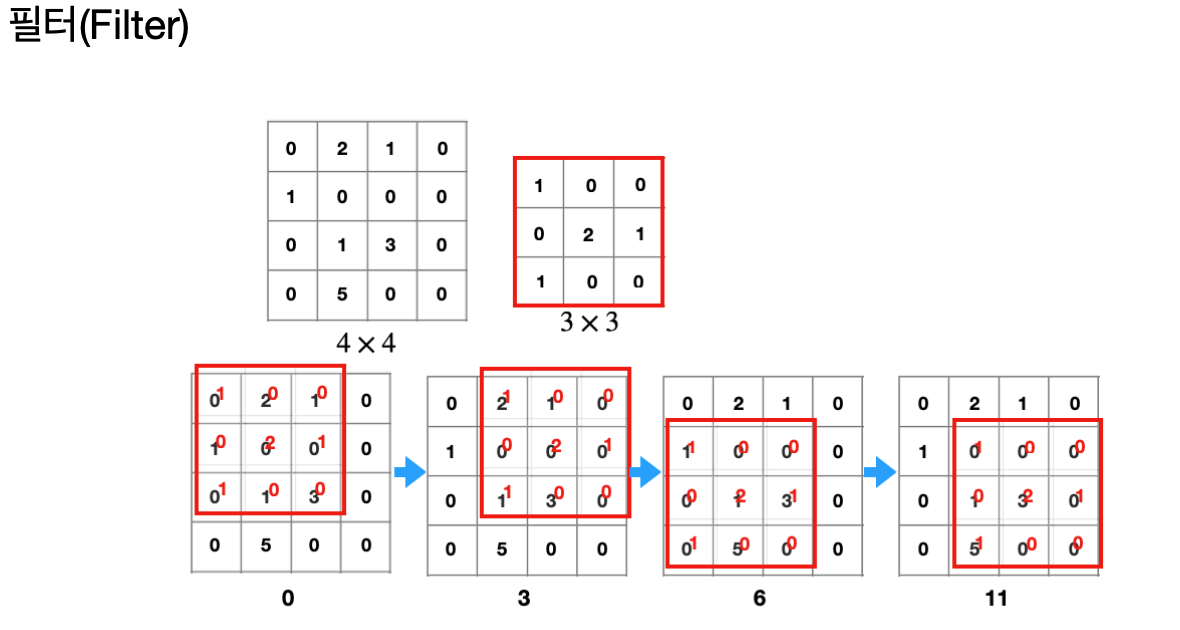
필터는 이미지의 특정 부분의 특징을 추출하는 역할을 한다.
예를 들어, 가장자리나 질감 등을 감지하는 데 사용된다.
필터를 이미지에 적용하면 해당 필터가 감지하는 특징에 대한 정보를 갖는 '피처맵'이 생성된다.
Feature Map
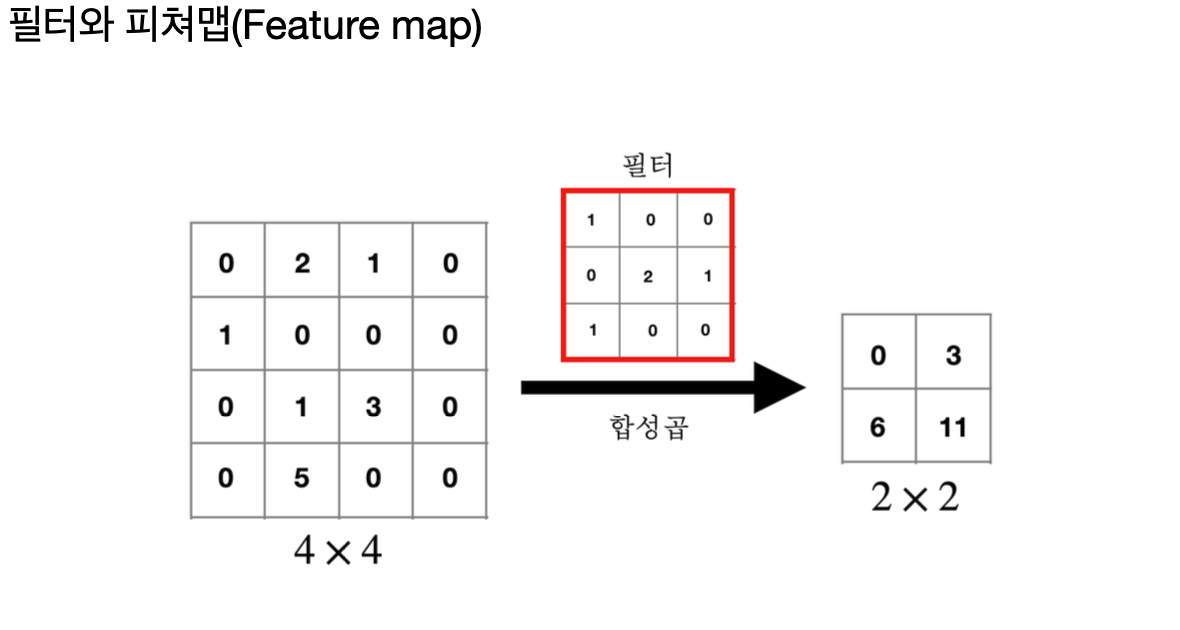
필터를 이미지에 적용한 결과를 피처맵이라고 한다.
이 피처맵은 원본 이미지의 특정 특징이 강조된 맵으로, 이미지의 핵심 정보를 담고 있다.
Stride, Padding
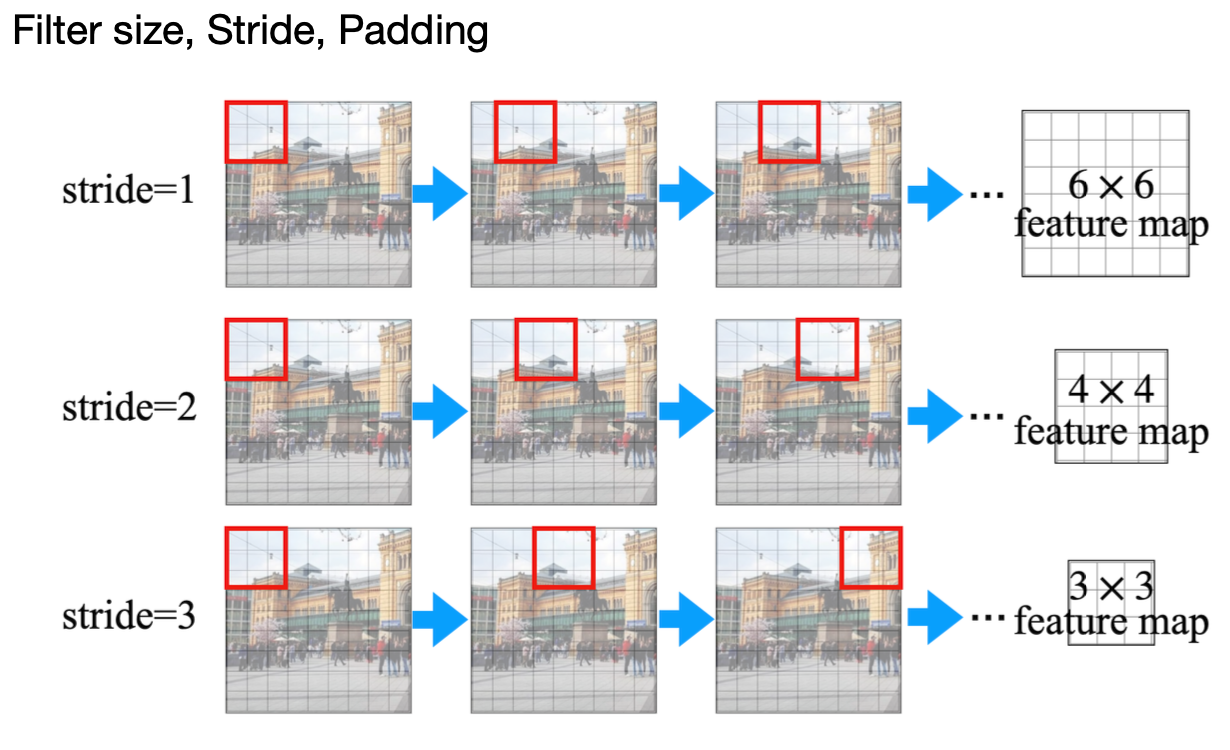
스트라이드는 필터를 적용하는 간격을 의미한다.
스트라이드가 크면 피처맵의 크기는 작아지며,
스트라이드가 작으면 그만큼 피처맵의 크기는 커진다.
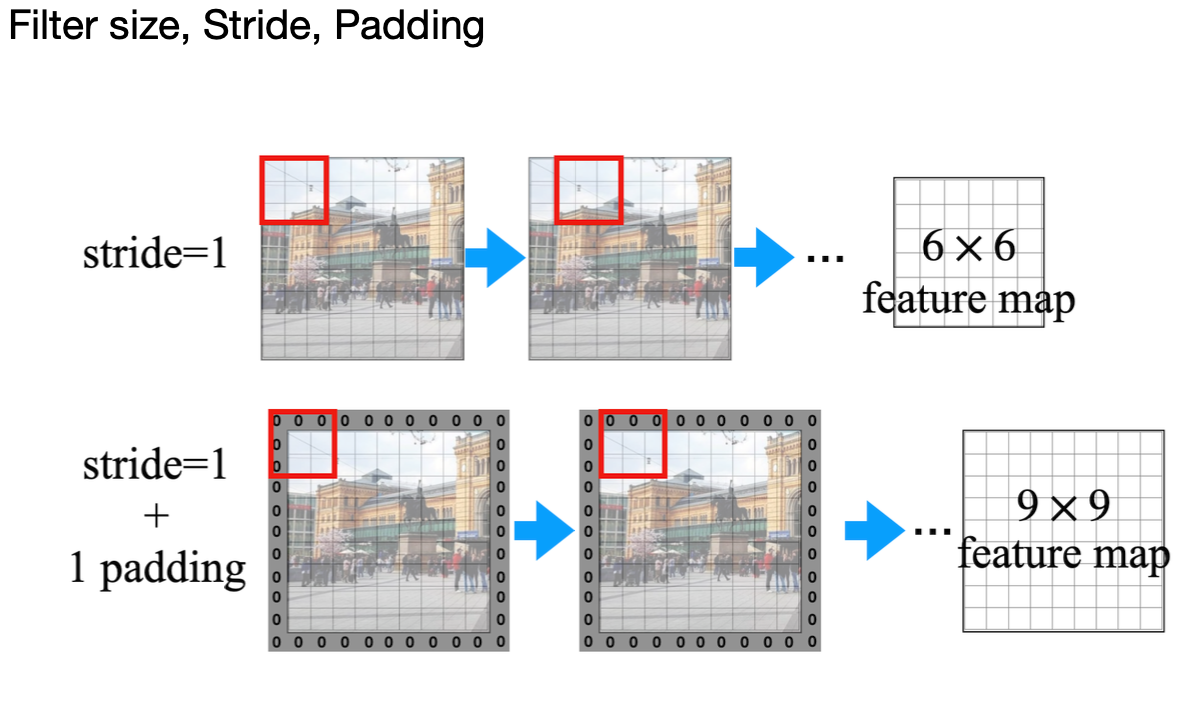
패딩은 입력 데이터의 주변을 특정 값(예: 0)으로 채워 넣는 것을 말한다.
패딩을 사용함으로써 필터 적용 시 이미지의 크기가 줄어드는 것을 방지할 수 있다.

Max and Average Pooling
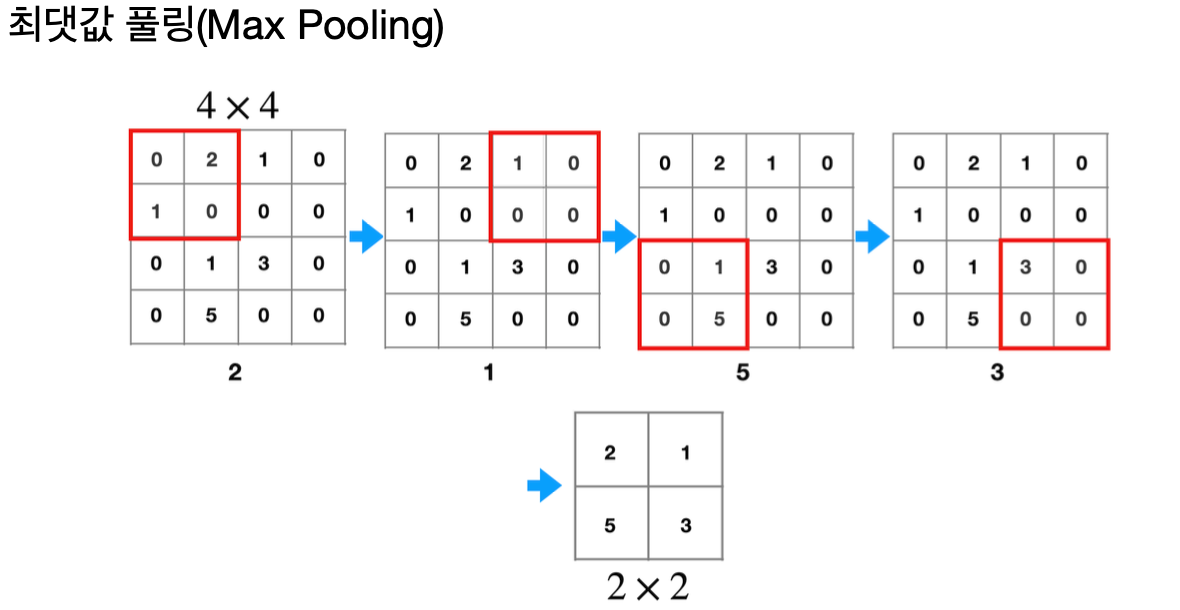
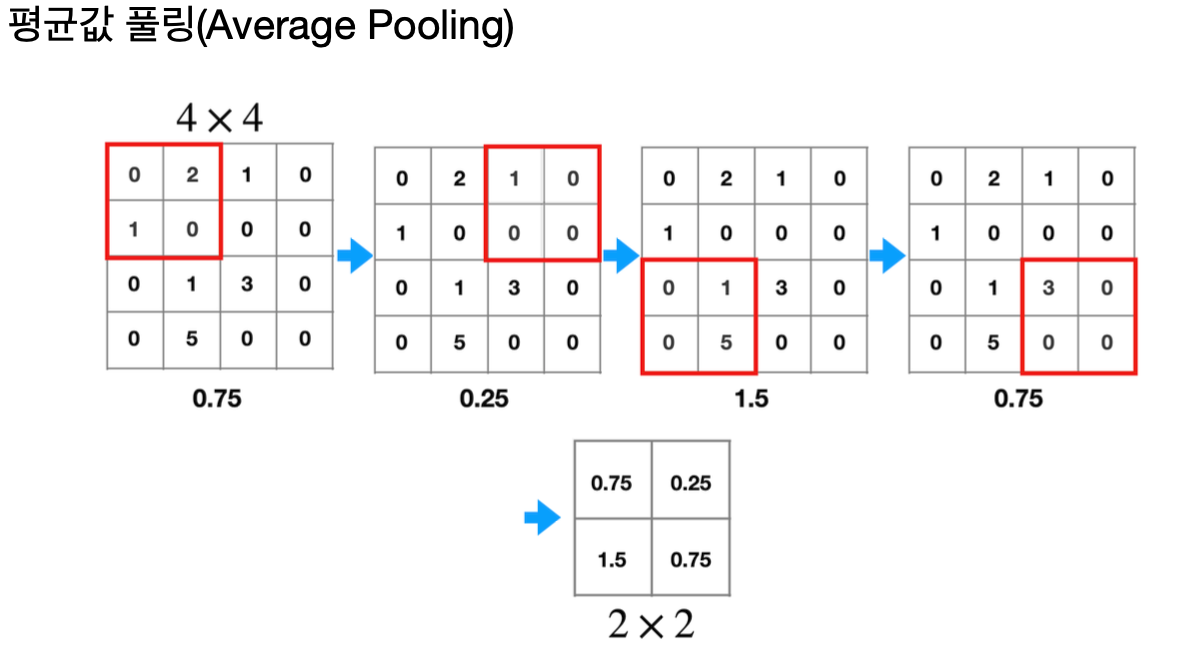
풀링은 피처맵의 크기를 줄이면서도 중요한 정보는 유지하기 위해 사용된다.
최댓값 풀링은 주어진 영역에서 가장 큰 값을 선택하는 반면, 평균값 풀링은 평균값을 계산한다.
이 과정을 통해 이미지의 공간 크기를 줄이면서도 중요한 정보를 유지할 수 있다.
Multiple Filters
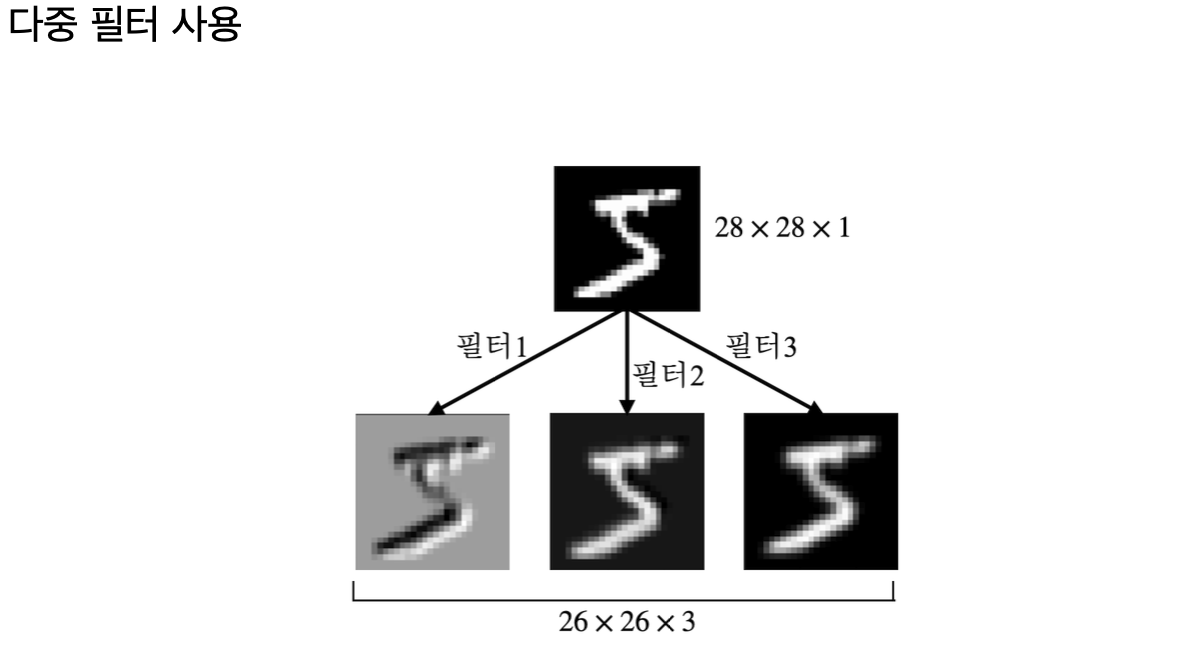
다양한 필터를 사용하여 이미지의 다양한 특징을 추출할 수 있다.
각각의 필터는 이미지의 특정한 특징에 반응하므로, 다중 필터를 사용함으로써 이미지를 더 잘 이해하고 분석할 수 있다.
Conclusion
합성곱 신경망(CNN)은 이미지 인식의 혁신을 가져왔다.
필터, 풀링, 다중 층 구조를 통해 복잡한 이미지에서 핵심 특징을 추출해 내며,
이를 바탕으로 이미지 분류, 감지 등 다양한 과제에 대해 높은 정확도를 달성한다.
이러한 기술은 의료 이미징, 자율 주행 차량, 얼굴 인식 등 일상생활 속 다양한 영역에 이미 깊숙이 자리 잡고 있다.
그러므로 CNN을 이해하는 것은 딥러닝의 세계로 나아가는 첫걸음이라 할 수 있다.
'ML+DL > Deep Learning' 카테고리의 다른 글
| 순환 신경망의 발전(The Evolution of RNN) (0) | 2024.04.10 |
|---|---|
| 순환 신경망(Recurrent Neural Network, RNN) (0) | 2024.04.09 |
| 합성곱 신경망(Convolutional Neural Network, CNN) (0) | 2024.04.07 |
| 컴퓨터 비전(Computer Vision) (0) | 2024.04.04 |
| 손실 함수와 최적화 (0) | 2024.04.04 |
| 기울기 사라짐(Vanishing Gradient) (0) | 2024.04.04 |
- Total
- Today
- Yesterday
- 기술면접
- 백준
- RX100M5
- 남미
- 스프링
- 세계일주
- 중남미
- 야경
- 세모
- 지지
- 리스트
- a6000
- 동적계획법
- spring
- Algorithm
- BOJ
- java
- 맛집
- 유럽여행
- 면접 준비
- 여행
- 스트림
- 알고리즘
- 파이썬
- 세계여행
- 자바
- 유럽
- Python
- 칼이사
- Backjoon
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |